
OpenAI的GPT-4o自发布以来,凭借其强大的多模态能力持续引领AI技术潮流。近期,其原生图像生成功能的正式开放,标志着文本到图像生成技术迈入了更精准、更智能的新阶段。与传统的DALL-E 3不同,GPT-4o作为真正的“全模态”模型,能够无缝融合文本、代码和图像的理解与生成能力,为用户带来前所未有的创作体验。
更精准的解析,更细腻的呈现
GPT-4o的核心优势在于其统一的训练框架。由于文本和图像在同一模型中学习,它能更精准地捕捉用户意图,生成细节丰富且符合逻辑的图像。例如,当用户输入“赛博朋克风格的未来城市,霓虹灯下有一家名为‘量子咖啡’的店铺,招牌使用荧光蓝字体”,GPT-4o不仅能准确渲染场景,还能确保文字与风格的协调性,甚至能根据后续指令调整霓虹灯的亮度或店铺的布局。这种交互式修改能力,让创作过程更加灵活高效。

复杂场景的突破性表现
此前的AI模型在处理多物体或复杂指令时,常出现属性混淆或定位错误的问题。而GPT-4o显著提升了“多物体绑定”能力,可同时处理15-20个独立物体。例如,要求“生成一张儿童生日派对海报,包含气球、蛋糕、卡通动物和‘生日快乐’的艺术字标题”,模型能准确分配颜色、形状和空间关系,避免将气球图案错误地叠加到蛋糕上。此外,其文本渲染能力也大幅进步,生成的菜单、标识或信息图表中的文字清晰可读,尽管小字号字体偶尔仍有优化空间。

从工具到创意伙伴的跃升
GPT-4o的图像生成不仅是技术升级,更拓展了应用场景的边界。教育领域,我们可以用它生成一幅讲述热力学第二定理的图片。或是让他生成一幅漫画风格的图片简单的讲述下草船借箭的故事。他都有不错的表现。
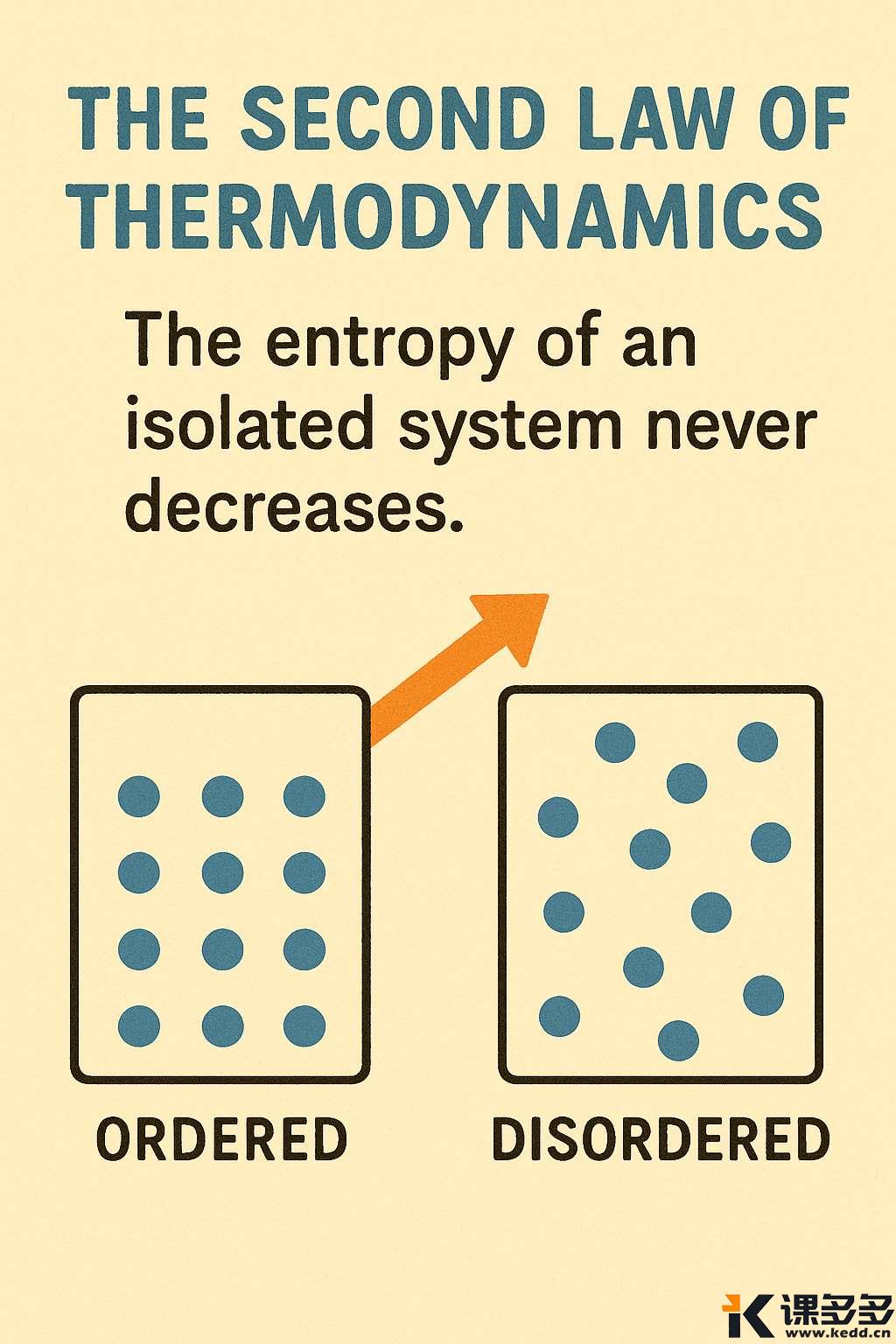

而且他不仅能完成这些,还可以随意转换图片风格,比如将上面草船借箭的图片改为3D风格。

GPT-4o的图像生成功能模糊了专业与业余的界限,让普通人也能轻松实现高质量视觉创作。正如OpenAI所言,这不仅是技术的迭代,更是“创意自由的新高峰”。未来,随着多模态技术的进一步融合,AI或将成为人类想象力最直接的翻译器——唯一的问题是,我们是否准备好迎接这场生产力革命的全面冲击?





暂无评论内容