
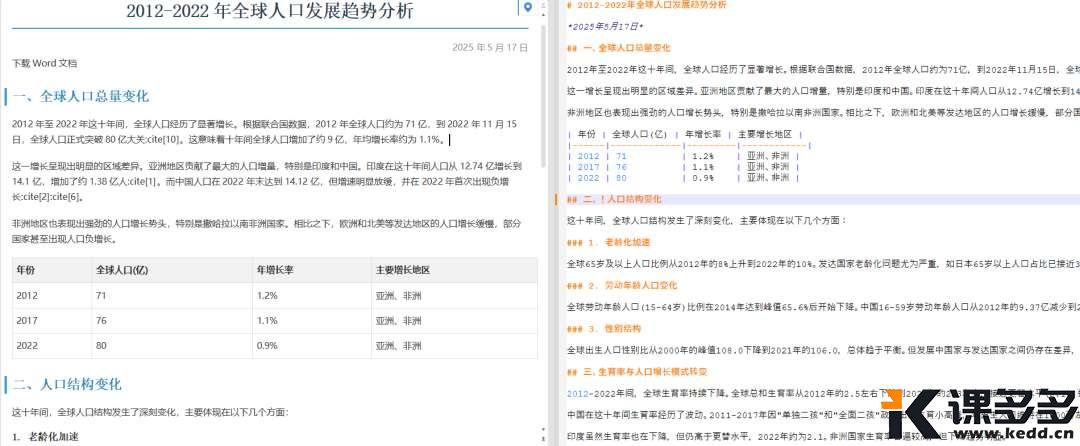
好的,老铁们!准备好迎接今天这篇炸裂级的干货了吗?!这绝对是生成式AI「一致性」问题的最佳解决方案(目前)。
还记得2025年1月初,各家 AI 模型还没有上线多参考图模式,当时有个项目的分镜是“同一场景但不同景别和角度”的镜头,解决方案如下:

在此之前,我用 Midjourney 跑了不下几百张图,只为了上下分镜不穿帮,最终还是另辟蹊径,选择了用运镜的方式,解决了这个问题。
💡 Tips:
举一反三,一部剧情完整的短片,很多分镜逻辑密切关联的镜头,同样可以采用这种方案,将运镜后的画面单独截图,再重新跑动态。
“新”时代的一致性攻略
AI 一天,人间一年,AI 应用上的技术问题,只要项目能延期,一切都不是问题了,因为,问题会随着 AI 技术的迭代自动解决。
除了上面最原始的单图运镜法,还有以下3种方案:
多参法
多参法的出现,让 AIGC 创作者省去了不少出图的操作,虽然这个办法很方便,但目前的技术版本,视频的效果比较糊。

多镜头法
即梦3.0视频模型的上线,衍生出了一种新的玩法——多镜头法(即梦3.0专属),用一张图即可生成“一场戏中的多个镜头”

多镜头法的视频的质量很不错,一致性保持的也很稳定,但是需要多抽卡,好在即梦的成本不是很贵,如果多镜头的某一个镜头动态不满意,可以单独截取一帧画面,另外跑动态。
全向参考法
就在今天,Midjourney 偷偷放出来新的一致性大招——「Omni-Reference」(全向参考),只能在 V7 版本使用。
操作简单粗暴!只需要上传一张参考图 🖼️,然后在你的指令后面加上一个神秘代码: --ow [数字] (比如 --ow 400,数字越大参考得越狠!)。✨
--oref [全向参考图 URL] --ow [权重值] --v 7.0
不只是脸!不只是衣服!它TM连指甲盖上的水钻 💎、背景里的一片树叶 🍃 以及画风都能给你精准复刻! 万!物!皆!可!锁! 🔒🌍 不管是人是物是鬼是神,只要有参考图,通通给你“克隆”出来!
这个部分,抛砖引玉,更多玩法待你解锁。
结语
AI 迭代的太快了,快到根本不需要焦虑用什么方案解决问题。
如果不急的话,有时候只需要把问题放一放🤣。







暂无评论内容