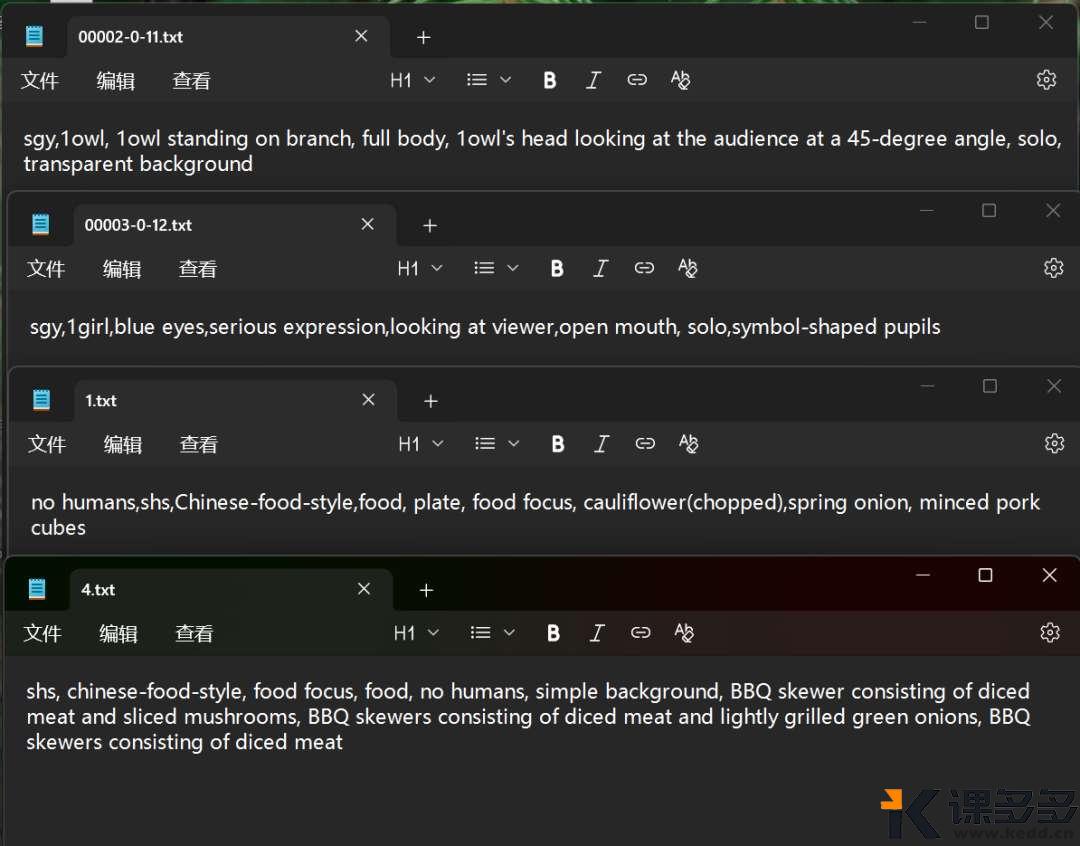
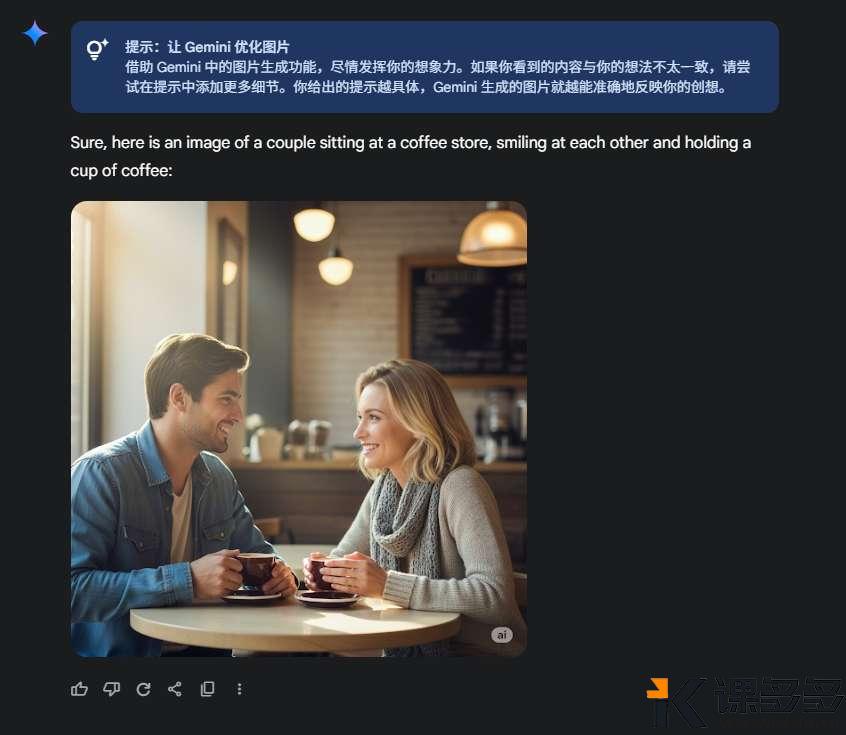
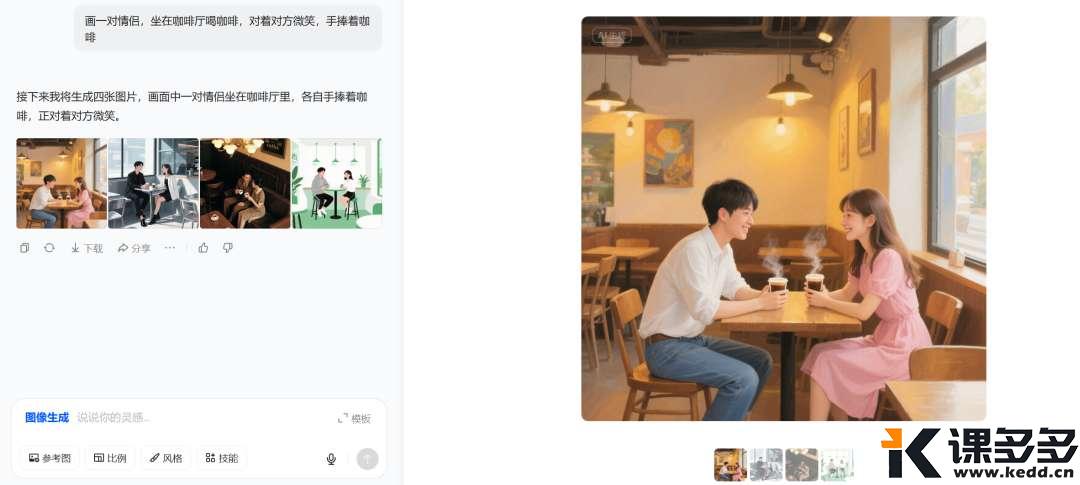
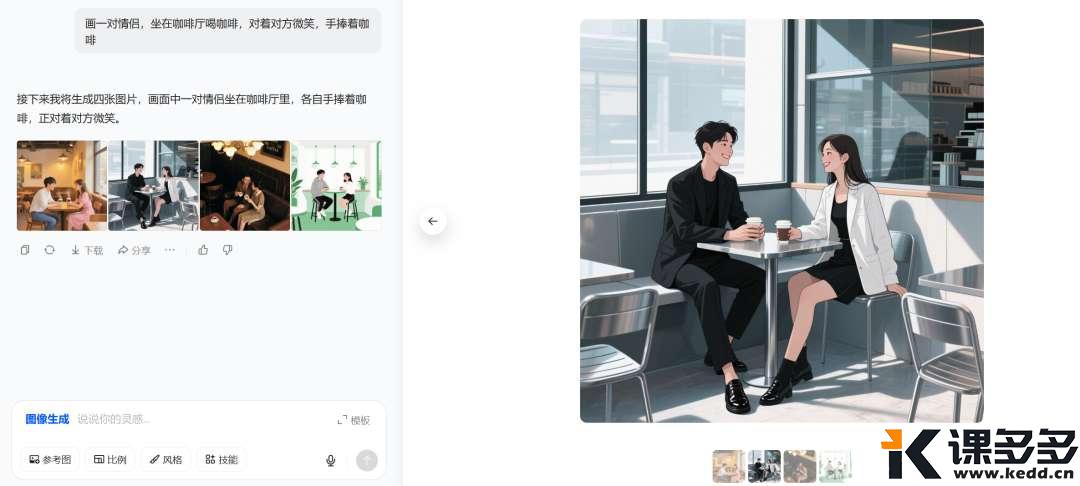
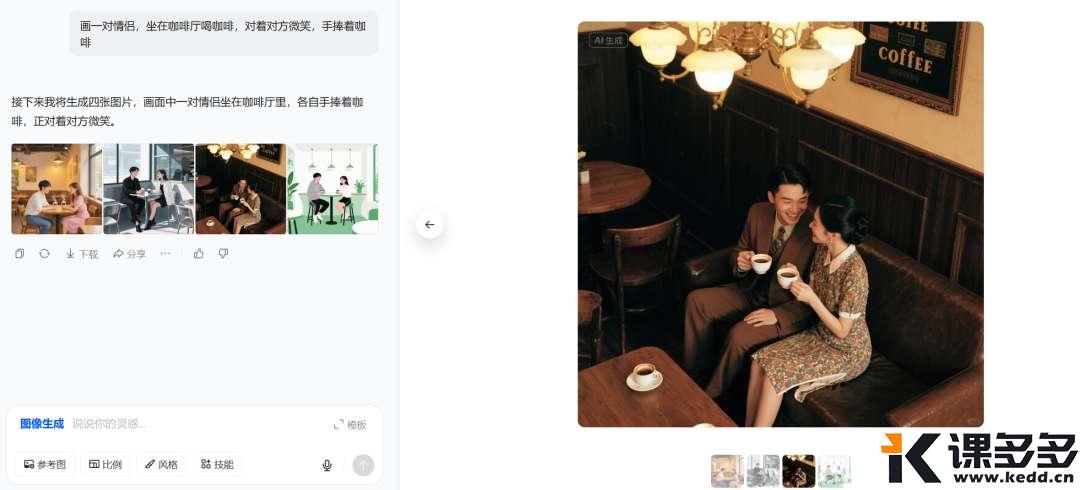
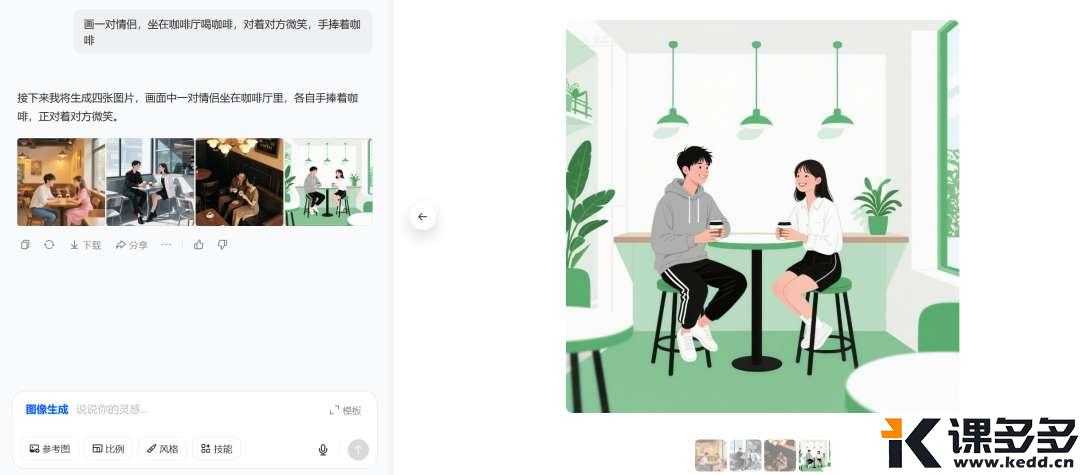
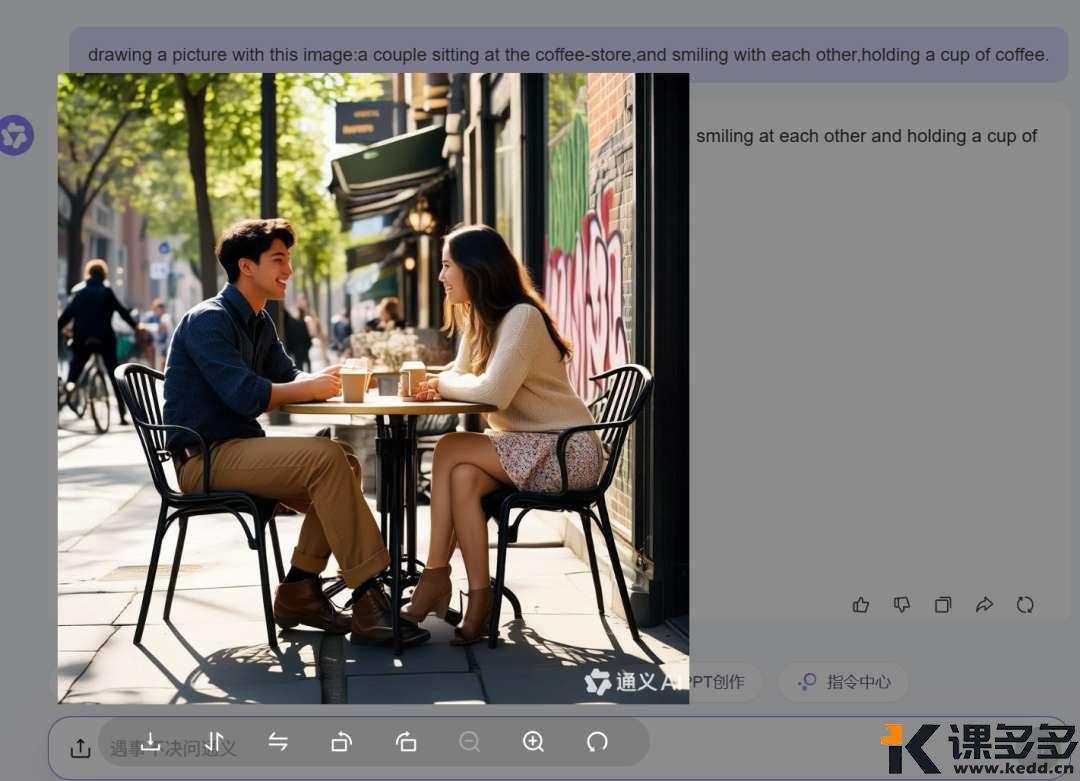
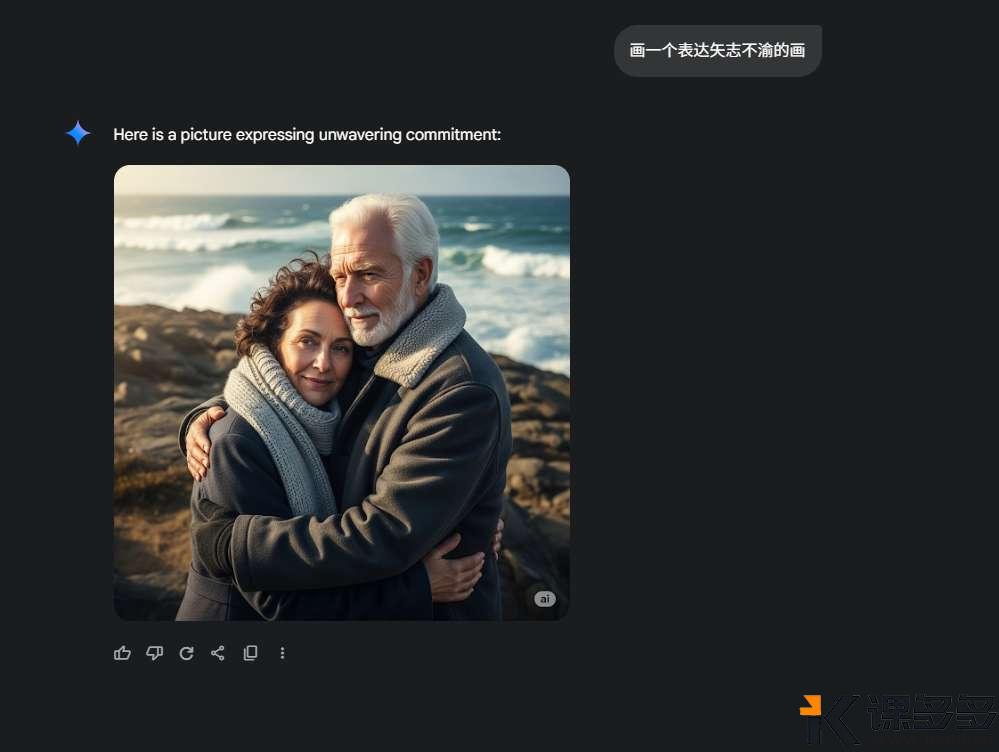
AI生图小结:为什么你生成的图片不是你想要的?课多多1年前发布06513 大家好呀,最近特别忙,因此有一段时间没有写东西了。前几天有位用户问到,瓶娘是怎么生成的,求一期详细的教程。 接下来要说的东西,可能并不会特别长,但足够干!学会了就不用给那些“AI生图”培训班交钱。不是说那些培训班没有用,也不是说它们教的东西就很水,只是围观了很久之后发现实际上它们提供的是工具的操作教程,而这些教程只需要自己上手操练几天,大概率都能学会,剩下的就是熟能生巧、善用百度(或谷歌)的问题。 首先,我们要深刻地了解一件事:AI(生图)大模型,真的能够理解我们的语义吗?而我们所说的“语义”,和AI理解的,是一回事儿吗? 先举个简单的例子,是我过往炼丹的一些数据标注,俗称打标。 一些数据标注的合集 上图是基于SDXL的数据标注,以单个词或简短词组为主,但不影响我们要探讨的一件事——AI理解的语义,是具体的物体。上面给出的标注都指向共同的目的:把一个物理世界存在的东西,用具体的词语给表达出来。 这就涉及到大模型的训练时候的一个重要的点:人工喂的数据,要打的数据标注一定是具体的东西,而不是抽象的。(这里特指的是生图方向的训练)。很多人画不好图地方就在这:人们总习惯性地把自己的输出刨除掉抽象的部分,认为自己的输出是“具象”的。 这句话有点难以理解。那么我们举个例子来说明。 比如说,你要画一对恋人在咖啡厅里喝咖啡,要怎么画呢?大部分下意识就是“a couple”起手,来描述一对“恋人”——这当然是没有问题的,但这是基于人类的逻辑。 事实上如果你用“a couple”来起手,你会得到什么? Gemini的结果 豆包(1) 豆包(2) 豆包(3) 豆包(4) GPT 通义千问 为了保证变量是稳定的,所以所有的提示词都是同一套: 这时候我们就会发现一个非常有趣的现象。唯一的变量“couple”,国外的大模型给出的是25+到35岁左右的人像;而国内的模型给到的是年约20-25左右的人像。 由于咱也不知道到底训练标注的时候是怎么定义couple的年龄、或者说到底有没有对年龄进行了特殊关系的说明,只能推测出“couple”这个抽象的词,在AI的语义理解里取决于训练师的标注是什么——如果标注的是年轻的人像为多,那么大概率各种Roll之后,它给出的结果维持年龄区间是在年轻人的分布概率更高;而如果标注的是中年人和年轻人混杂,那Roll出来的结果有可能会2个年龄段混出。 但——问题就来了:这暴露了人类下意识的判断,即人类在日常生活中对抽象词汇的使用和理解,远超我们的想象。甚至可以说,我们习惯认为我们说的都是具象的词。这里其实还出现了一个小小的知识点:大模型的偏见问题。“Couple”其实不是某个年龄段的专属,但大模型表现出来的却是有偏见的。 这也就解释了为什么总有人说AI画图画不出来自己想要的,也很好地说明了为什么在最开始AI生图刚出来的时候,各种教程都一定会告诉我们,想画什么样的图,要把画面描述清楚。 很多人觉得,我已经描述清楚了啊?请注意,这个清楚仍旧是一个抽象的词。更具体的说法是:你必须要学会从你的头脑中解构出你“想要”的画面里,应该出现的具体的物品。 比如,你想要画一幅表达矢志不渝的画,那你直接搓Prompt:画一个表达矢志不渝的画,大概率是画不好的。 现场演绎:从上到下-GPT、Gemini、豆包 回到小伙伴问的:怎么画出瓶娘来呢? 让我们先第一步:解构画面。瓶娘从字面意思理解,就是瓶子+二次元女孩。我们想要表达这种微缩的场景,那必须要在提示词里保证二次元女孩是在XX物体中的,或者是被装进一个小型的XX物体中——注意,这里就是具象的词了——“装进”、“坐在”、“站在”。紧接着我们希望画面非常丰富,那二次元女孩的穿着打扮是必然要强调的,因此可以详细的描述二次元女孩穿什么、戴什么饰品、做什么样具体的动作、有什么样的面部表情、肢体到底应该怎么摆放。做到这里就足够了? 当然不是。我们都知道现实中是不存在这样的东西的,即便是存在也是一些手工做的物体才存在,因此我们必须要强调这是“超现实主义”的风格,只有强调是“超现实主义”,模型才能够将以上的上下文理解并且组合的时候不会出现正常尺寸的二次元女孩拿着瓶子。无他,因为后者在大模型看来,才是“合理的”——因为在训练数据上来说,人类喂的数据和标注的组合正是如此,如果没有超现实主义的加持,对模型来说输出结果出了以上所说的,还非常有可能出现这样的情况:正常尺寸的二次元女孩和瓶子的支离破碎的强行组装。 由此引申,当我们准备用AI复刻大师级的照片、电影画面的时候,必须要关注这个画面中真实存在的东西是怎样的,而并非它传递的氛围。 看到这里,你学会了吗? © 版权声明文章版权归作者所有,未经允许请勿转载。THE ENDAI笔记 喜欢就支持一下吧点赞13 分享QQ空间微博QQ好友海报分享复制链接










暂无评论内容