
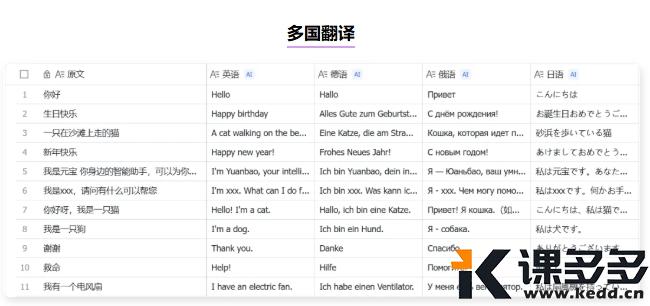
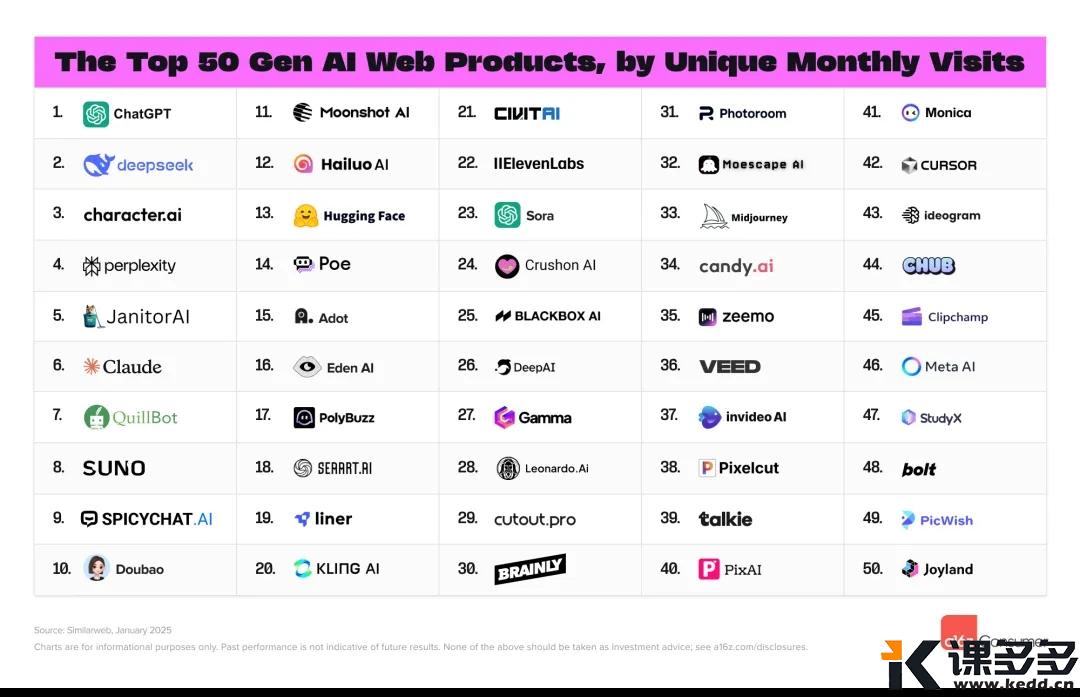
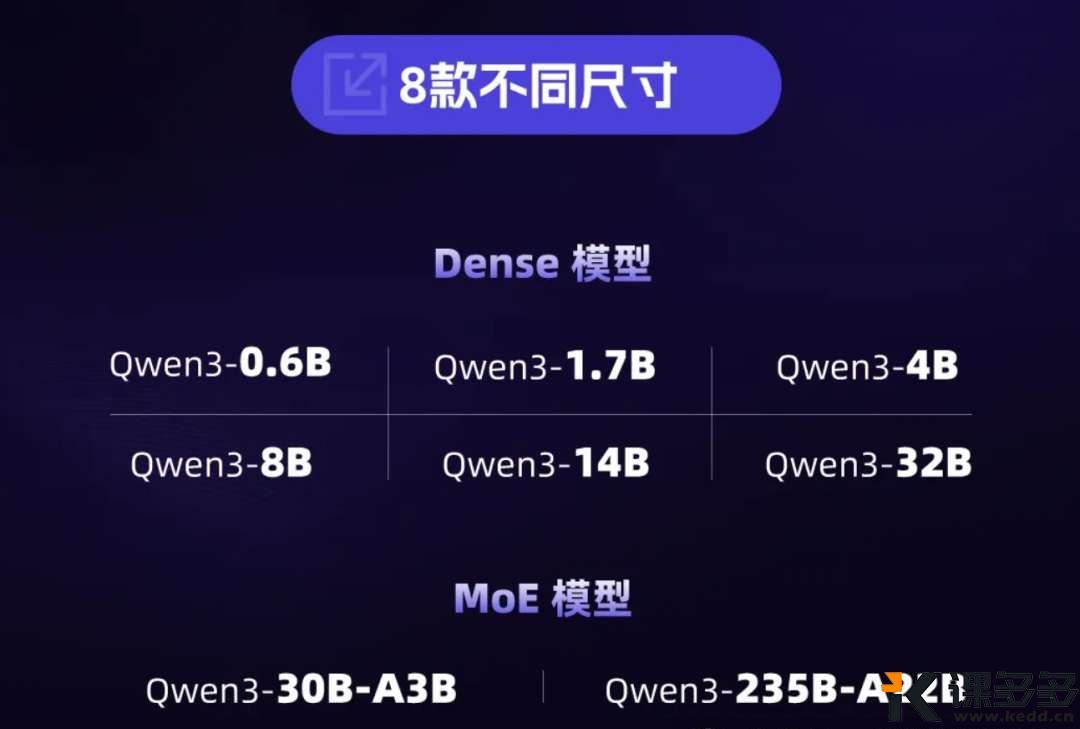
短短两天,大模型界又变了天。葉子用最简单的语言给大家捋一捋。
一、DeepSeek开源
从昨天开始,进入到 DeepSeek 开源周。
第一天,开源了FlashMLA。
可以提高 LLM(大语言模型)推理效率,提升高端GPU的性能。
使用 FlashMLA 代表着更低的成本、更快的推理,更高的 GPU 利用率。
简单理解,就是计算机升级了,可以更快地处理信息,AI对话速度也会更快。
第二天,开源了DeepEP。
一个专为混合专家系统(MoE)和专家并行(EP)定制的通信库。
使用 DeepEP 可以提升计算资源分配能力,更快速处理大量数据,同时提升数据传输速度。
简单理解,降本增效拉满,可以提升大规模 AI 训练和推理的效率。
不得不说,DeepSeek 才是 “真OpenAI”。
二、Claude3.7上线
在DeepSeek开源的第二天,Claude开始搞偷袭。

Claude家族第一个推理模型Claude 3.7 Sonnet上线。
然后,还要发布一款属于他们自己的AI编程工具Claude Code 。
Claude 3.7 Sonnet是一个混合推理模型。意思是,他既是一个普通模型,也是一个推理模型。
相当于既是DeepSeek-V3,也是DeepSeek-R1。不过实际使用中发现,需要使用下拉菜单去切换,会出现在不同对话框。
这点让葉子极其无语,又需要切换,又不在一个对话框,那么和两个模型有什么区别?
当然,Claude 3.7 Sonnet也表现出了非常优越的性能。一如既往的在写代码上,吊打了包括o1,R1等各大模型。

一口气写3200多行代码,就问一句,还有谁?
三、阿里Qwen亮相
今天上午,阿里Qwen团队在 QwenChat 发布了推理模型——深度思考 (QwQ) 。

这是阿里首个推理模型,同时支持深度思考和联网搜索。
体验地址在此: https://chat.qwen.ai
团队声明,即将发布QwQ-Max 正式版,同步发布手机端的APP。
四、豆包小范围测试深度思考模型
今日下午,有部分用户在豆包APP和官网体验到了推理模型。
据豆包相关负责人表示,目前内测的是自研推理模型的不同实验版本,而非接入DeepSeek。
根据不完全统计,目前国产大模型具备推理模型的有:
通义QwQ、混元T1、智谱GLM-zero、Kimi-K1.5、星火x1、天工o1、跃问R-mini、百小应M1。
推理模型目前基本已经是各大模型厂商的标配了。
这些就是这两天大模型的一些变化。葉子仿佛看到了又一场大战一触即发。
但这次,我们的国产大模型一定是牌桌上最重要的一个。


暂无评论内容