
之前跟大家讲过,使用一张人物的正面照,然后使用视频生成,再生成三视图,详情可以看这篇:AI 短剧特训 | 如何正确输出人物的三视图
但是最近发现一个改图工具可以更好地解决这个问题,大家猜猜是啥。
这种是很明显的文改图,所以,第一时间自然是想到了豆包和 ChatGPT 4o 了。
我们先准备好一个头像:

先来试试豆包,官网:https://www.doubao.com/
帮我生成该头像的全身照

em…好像,这差别有点大啊,感觉就是仅保留一些特征,然后生成了。
我们再换 ChatGPT 4o 试试,官网:https://chatgpt.com/
请根据该头像,生成全身照

是不是还不错!
但是实际上,它会偷偷给你改细节的,这也是为啥后面我很少用 ChatGPT 4o 的原因,我截图给大家对比看看:
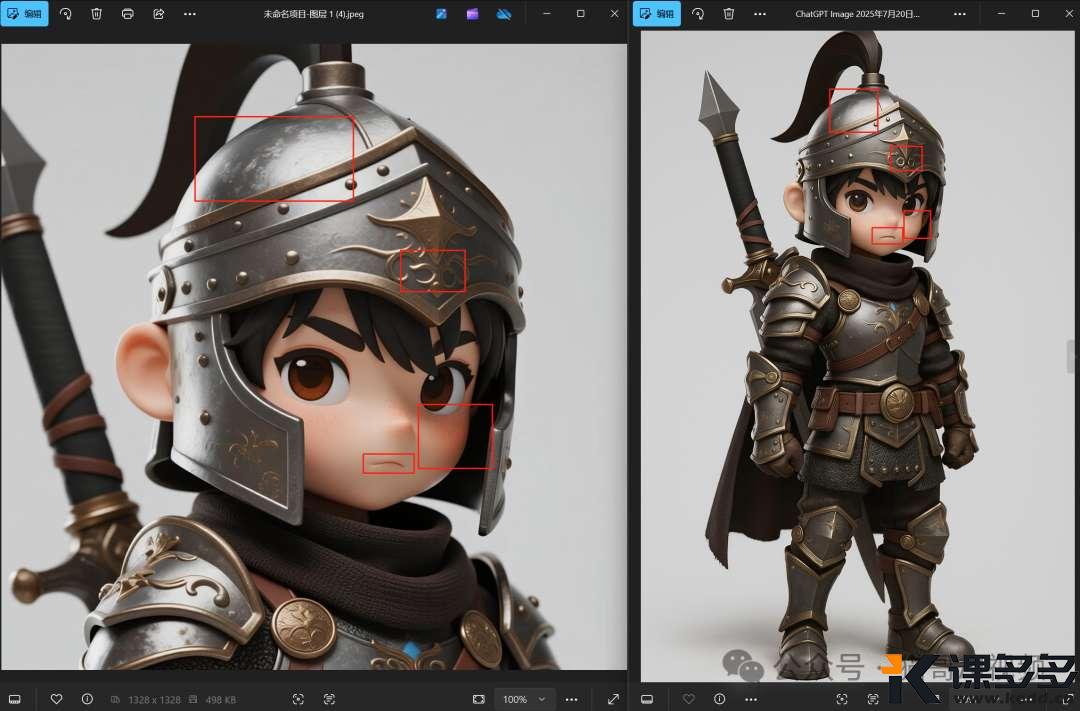
是不是很明显,腮红,嘴型,盔甲纹路啥的都给你改掉了。
不过整体确实还行,可以当做备选方案。
我们再试试让他生成三视图看看:
再生成该人物的全身照三视图,分别为正面,侧面,背面

em…这效果就比较难评了,居然连人物比例都改了,而且有两张连剑都不见了。
备选备选。
我们再换个工具,FLUX.1 Kontext,可以本地部署,这样就能免费使用了。
不过我还没写教程,想要的小伙伴可以留言下,多人的话,我补篇好吧。
我们也可以用线上的其它平台,需要积分:https://www.xingliu.art/
打开官网后,我们选择“F.1 Kontext”:
我们上传图片后,填写提示词,再点击“生图”:
请根据该头像,生成全身照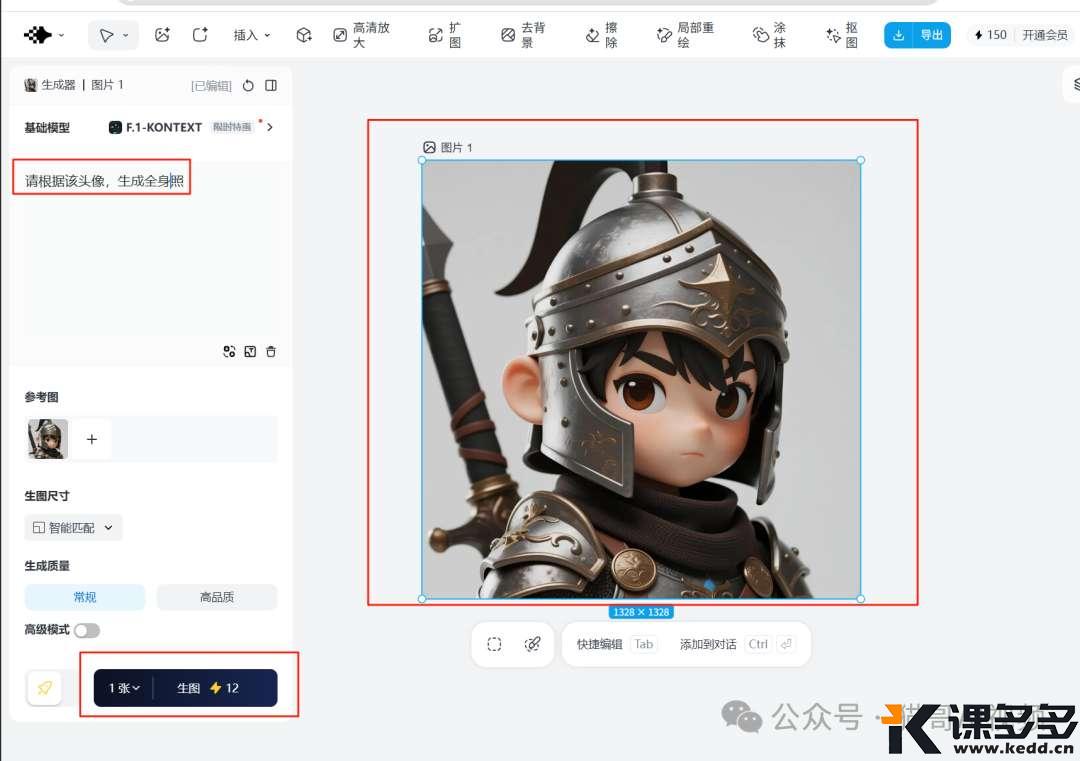
我们看看效果:
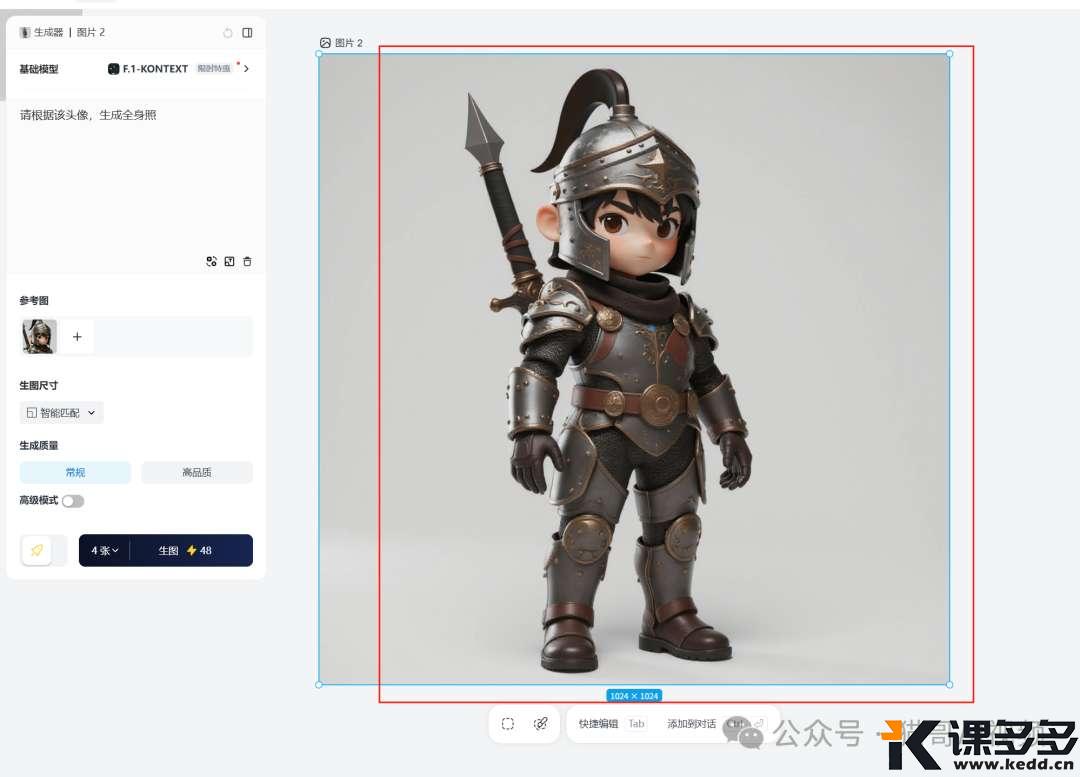

截图对比下:
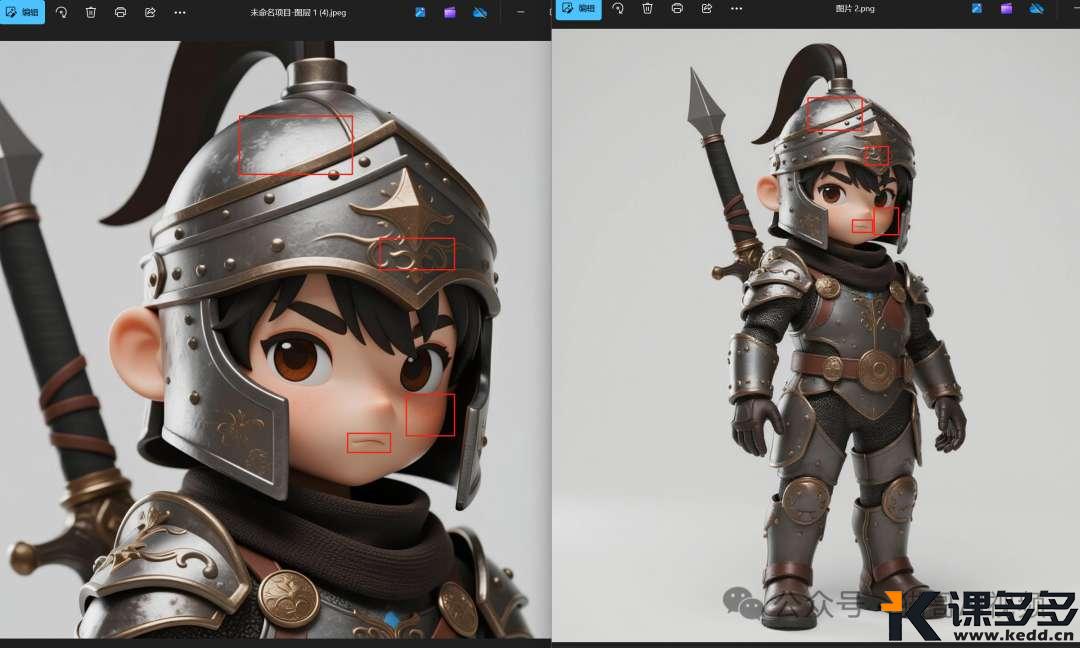
大家可以看看,这些细节都保持得非常好,这一致性,无敌了!
但是,这剑好像,底部不见了,难顶。
我们再尝试下三视图:
根据该图片生成人物的全身照三视图,分别是正面,侧面,和背面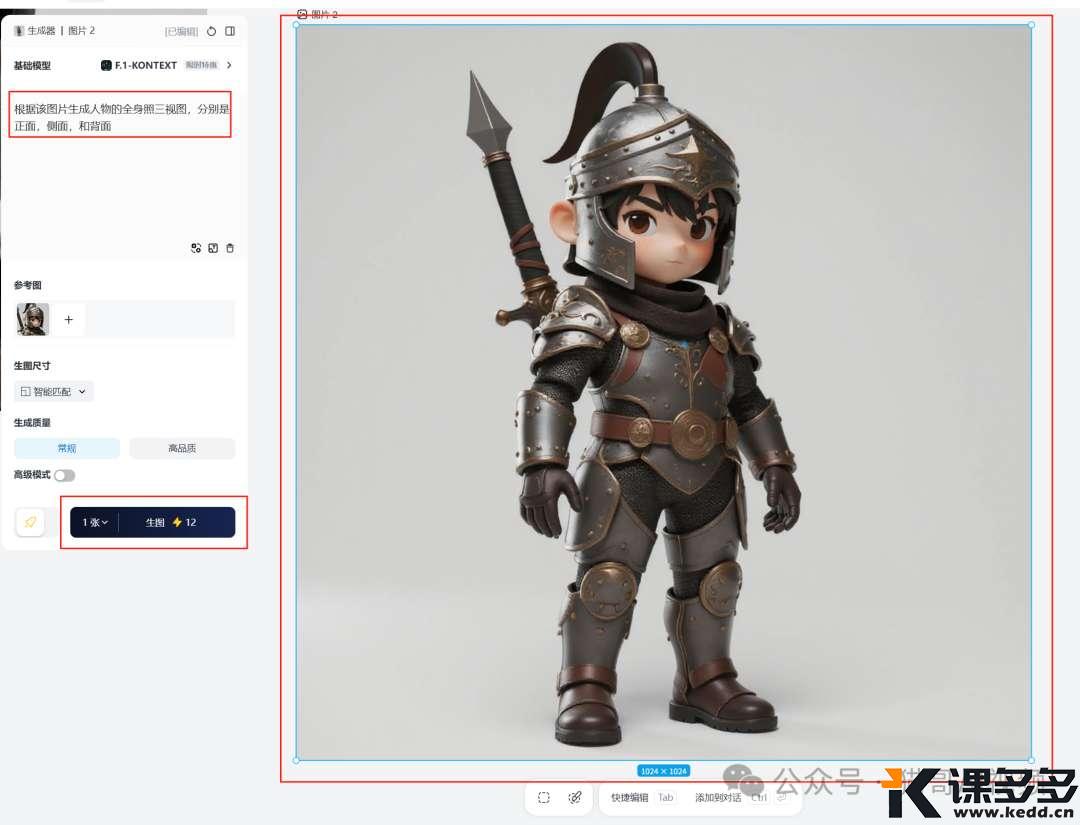
我们看看效果:
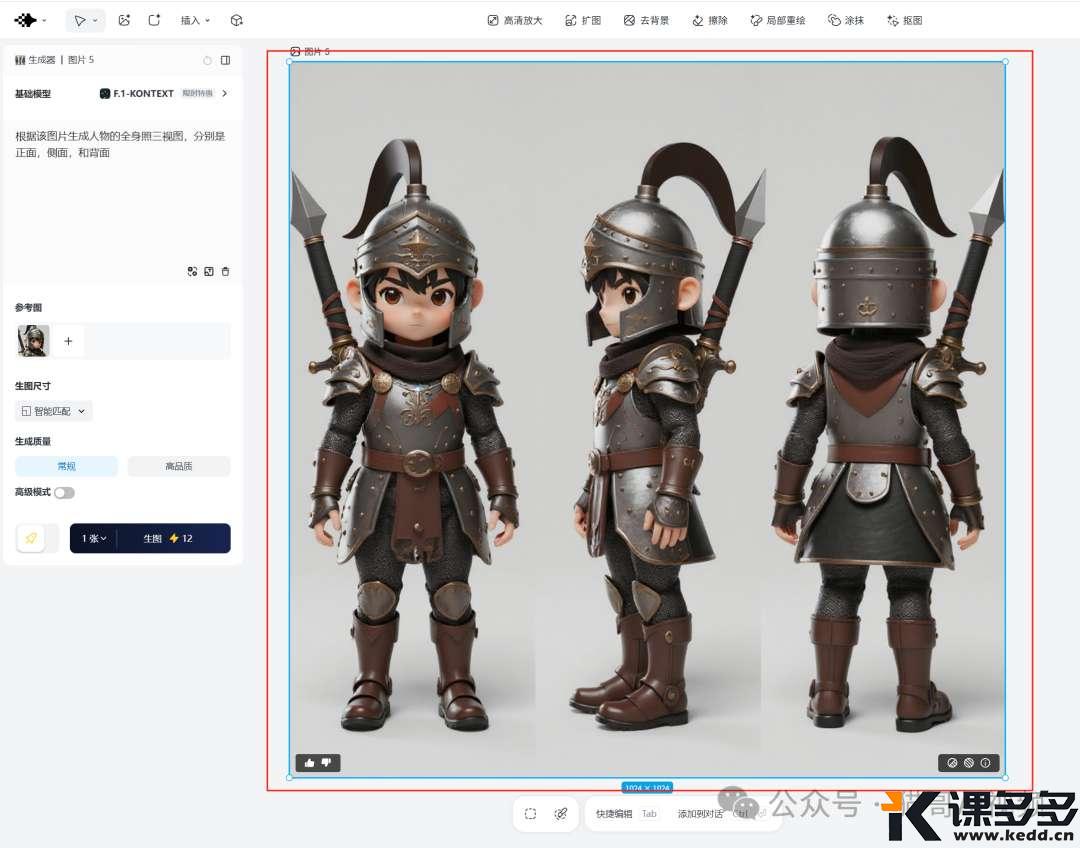

人物一致性确实保持得不错,但是背后的剑确实是个问题。
所以 F.1 Kontext 在纯人物上保持还是不错的,但是像人物背后的物品确实容易出问题。
那我们就可以采用 ChatGPT 4o 生成人物图,然后再用 Kontext 生成三视图:
根据图片里面的人物,生成全身照三视图,分别是正面、侧面、背面这里我们调整比例为 “16:9”:
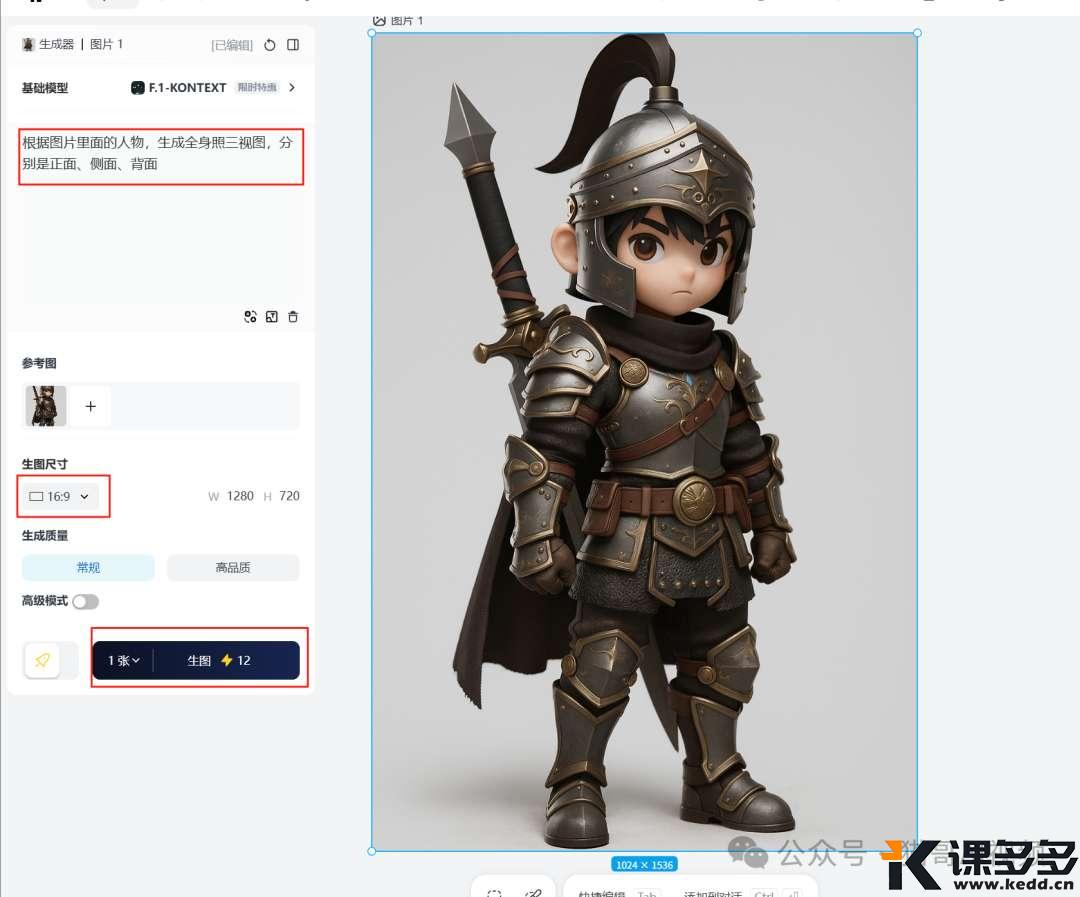


虽然中间的人物少了一把剑,人物的一些细节也改了,但是,综合来说,这个就是最佳结果了。
目前的 AI 工具总是会有一些特别的缺陷,还不能完美使用,大家可以根据自己的需求,组合 AI 工具进行使用。
人果然才是最重要的!脑子要灵活一些。

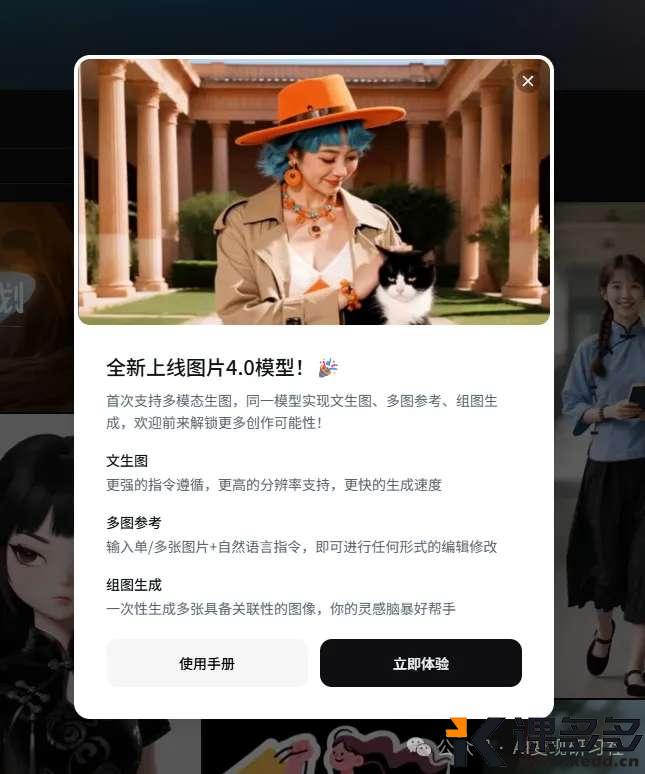






暂无评论内容