
想象一下,在未来用 AI 制作逼真的电影级人物角色以及对话,就像资深的老戏骨演戏一样简单,听起来像是天马行空?好吧,系好安全带,因为这一天来得比你想象的要快!
今天,Meta GenAI 部门研究刚发布了一项非常酷的技术,名为 MoCha。这是一个 AI 模型,它不仅能生成与音频完美同步说话的角色视频,还能展现出逼真的情感和自然的动作。
用首席研发人员魏聪自己的话说:
MoCha:电影级别能说会动的虚拟人技术
⭐ “能说会动的虚拟人”,直接用大白话和语音就能生成活灵活现的角色动画。
⭐ MoCha 模型,是头一个用 DiT 架构,能做出电影级别虚拟人的系统。
⭐ MoCha 第一次实现了多角色对话,还能按顺序轮流说话,动作表情也特丰富,直接把 AI 自动讲故事这事儿往前推了一大步。
说到这里,有没有联想到上个月正式上线的 OmniHuman-1 ,也就是即梦 AI 对口型的大师模式。具体内容参见:即梦OmniHuman-1:目前AI对口型最好的模型,没有之一!
MoCha 又有什么不同?
那么,MoCha 到底有什么特别之处呢?🤔
一直以来,现有对口型技术就像是“会说话的头”,就只有脸和部分肩膀动作。
但 MoCha 不同,它可以创建 全身对话角色,意味着可以拥有一个鲜活的数字人,他可以走路、做手势并与周围环境互动,同时进行自然的对话!🤯 这简直将 AI 数字人向电影级别迈进的一大步。
举个例子:


上面两个例子,很明显,Mocha 的技术,可以让人物走动,而 OmniHuman-1 只是让人物有感情地说话,虽然肢体动作也挺丰富。
❓也许,这个问题是即梦 AI 大师模式不支持提示词引导导致?
想想看,你可以描述一个角色、环境以及所说的话,而 MoCha 可以将其栩栩如生地展现在屏幕上。它甚至可以处理多个角色之间的来回对话!有没有脑子里的画面全出来了的感觉?
MoCha 技术实现
以下内容来自研究论文原文[1]。
MoCha 是如何实现这种魔法的呢?✨ 它使用了一些巧妙的技术:
-
• 端到端训练(无需额外帮助!): 与一些需要额外信息(如参考图像或骨骼)来引导它们的旧 AI 模型不同,MoCha 直接从文本和语音中学习。这使得过程更简单,并允许更丰富和自然的动作。 -
• 语音-视频窗口注意力机制(完美的口型同步!): 你有没有看过配音很差的电影?嘴唇和声音对不上,非常令人分心!MoCha 拥有一个特殊的系统,可以密切关注音频,并确保角色的嘴唇动作与语音完美同步。🎤 -
• 联合语音-文本训练(逼真的动作!): 为了使角色移动得更具说服力,MoCha 从包含语音和文本描述的视频中学习。这有助于它理解人们在说话时如何自然地移动和做手势。 -
• 多角色对话生成(AI 伙伴!): MoCha 首次能够创建包含多个角色进行连贯对话的视频,就像电影场景中一样。他们甚至可以轮流说话!👯
为了测试 MoCha 的效果如何,研究人员创建了一个名为 MoCha-Bench 的特殊测试。他们将 MoCha 与其他现有的 AI 模型进行了比较,你猜怎么着?
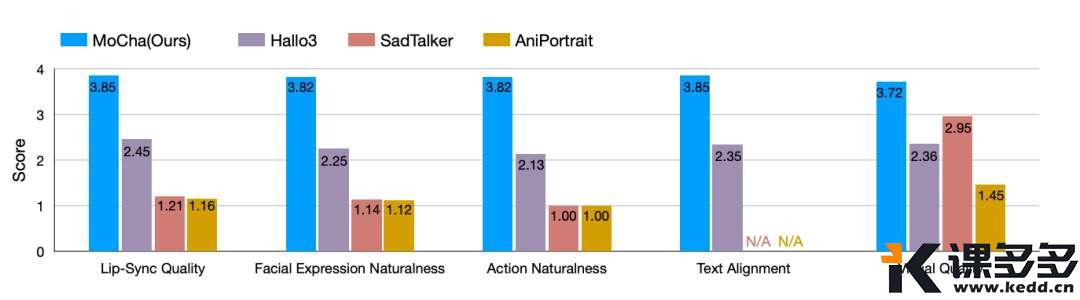
MoCha 完胜!🥇 它在口型同步、展现自然的表情、执行逼真的动作以及整体视觉质量方面都表现得更好。
很奇怪(尴尬),这里为什么没有 OmniHuman-1。
结语
这下,压力又给到了即梦 AI 大师模式(OmniHuman-1),MoCha 代表着以 AI 驱动的视频生成(对话技术)的一大进步。
它不仅仅是让角色说话,而是创造出可信的、富有表现力的数字生命,可以彻底改变电影制作,到创建更具吸引力的教育形式,和更逼真的虚拟数字人助手。
相信以 MoCha 为代表的 AI 数字人对口型技术,让视频创作的未来变得更加令人兴奋!🎉 我们拭目以待吧!






暂无评论内容