

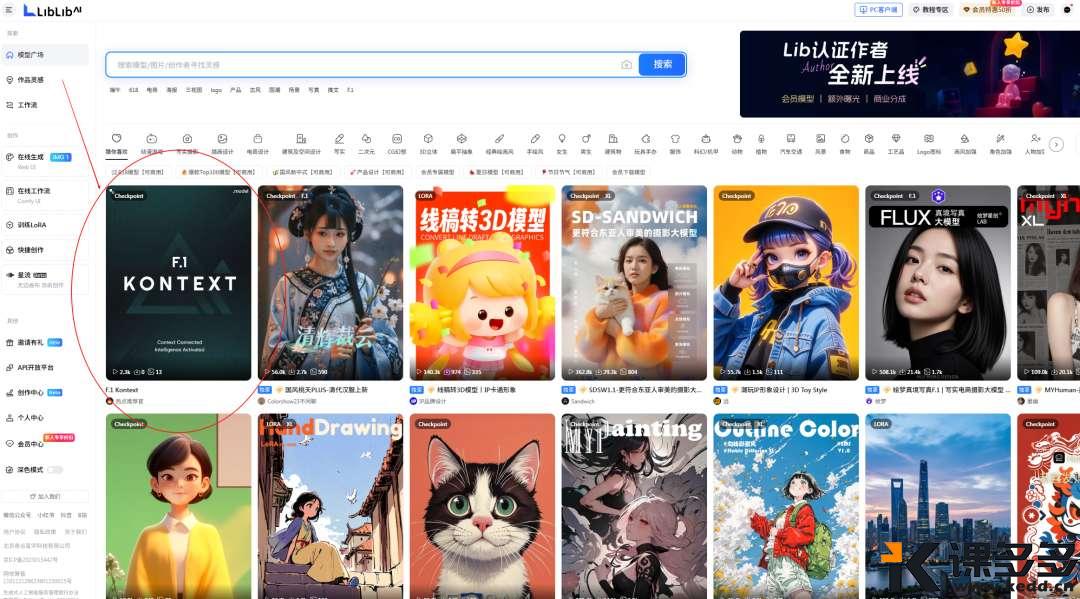
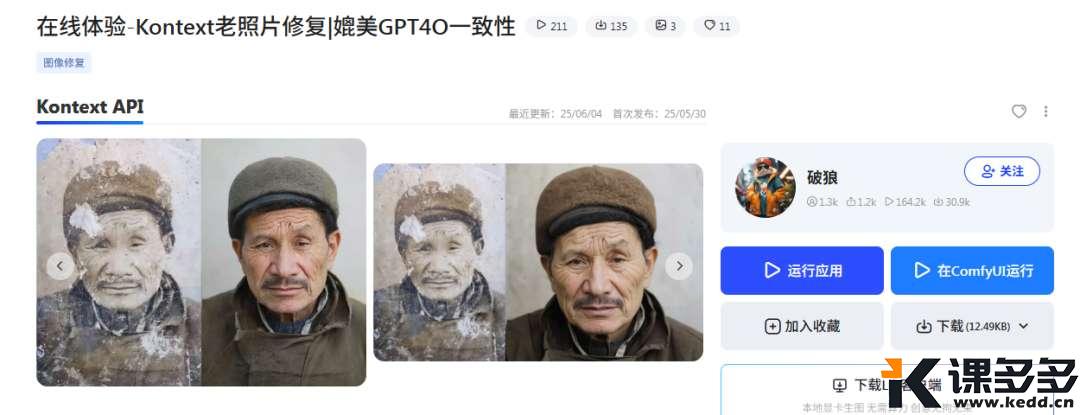
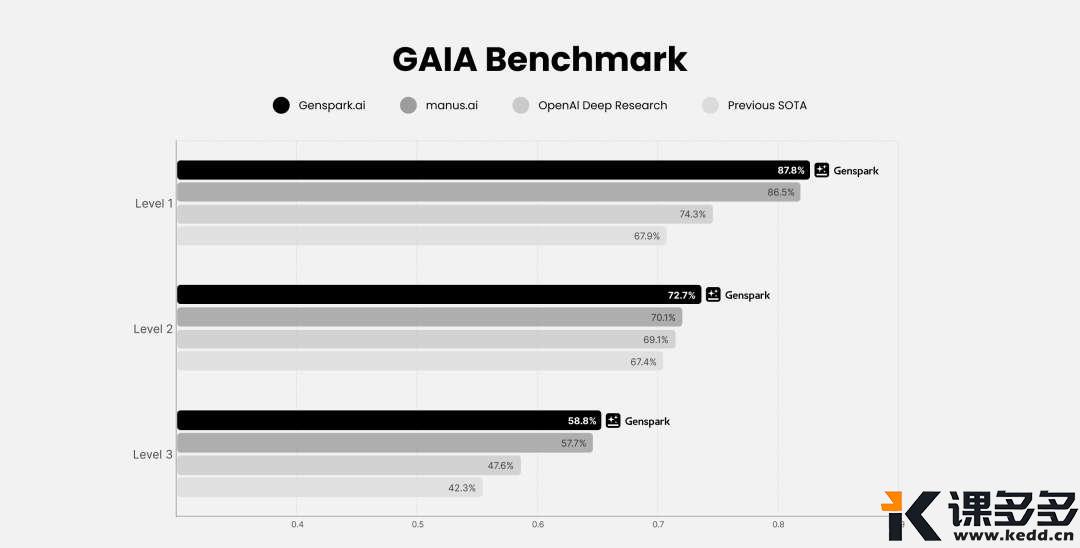
号称:全功能版本的Kontext一向敏锐的雪佬注意到了这一点,这不得测一下,
🔘于是就赶紧打开了Lib官网,
网址如下:https://www.liblib.art



The background is a studio backdrop painting,featuring landscapes,pavilions,and pagodas. These elements can be colored based on the scenery (e.g., mountains in teal/green or ochre, sky in light blue, building tiles in gray or cyan/blue-green, pillars in red, etc.).,
Please ensure the overall color palette is harmonious and reflects the simple,unadorned style of that era.,



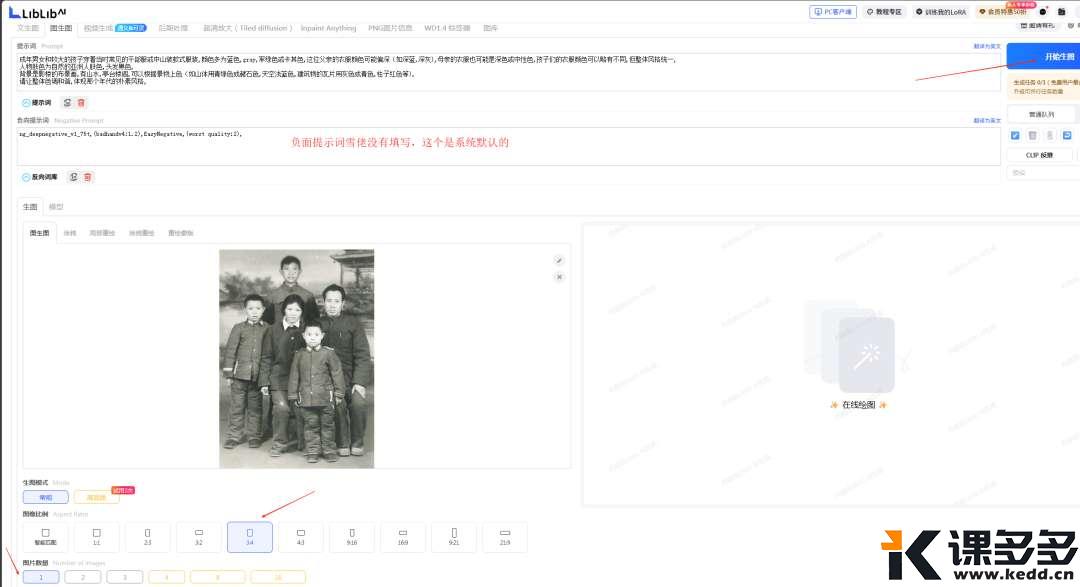
Change the car in the image to a farm tractor.,
把图片中的汽车改成农用拖拉机。
好,咱们继续下一个测试,
模特脸部的正面图,改成侧面图,

是不是感觉这是同时拍的一组照片,
人物特征和场景风格都还原的没毛病。
提示词:
Convert the character to a profile view while maintaining the composition,color,tone,lighting.,
将人物转换为侧面图,同时保持 [构图/角色/色调/光影] 不变
再来上个强度,让它变成吉卜力风格试试。
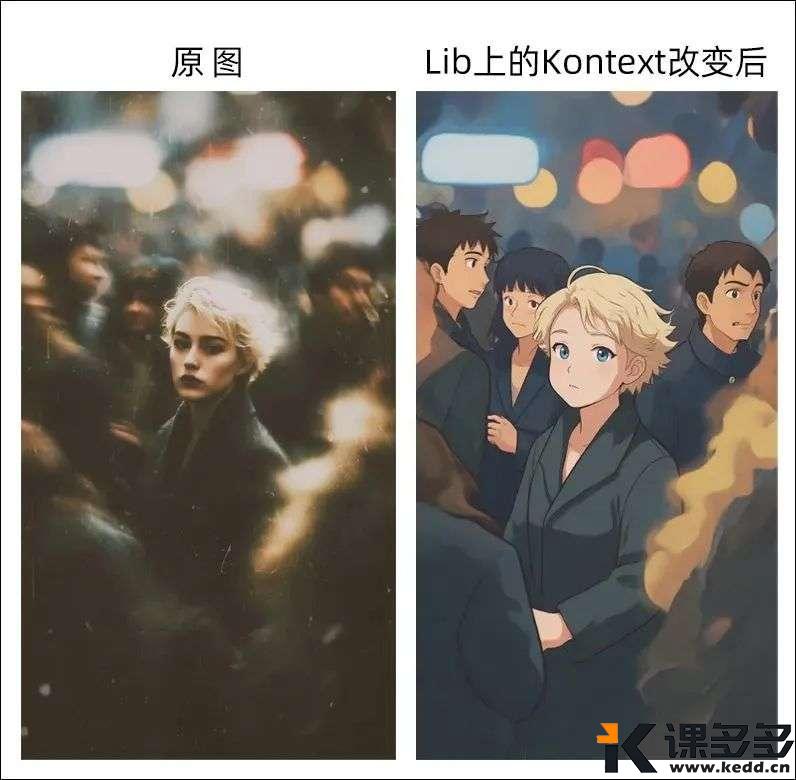
转换为 [吉卜力风格],同时保持 [构图/角色/其他] 不变
继续测试,

以及空中散落的花瓣,
一下就把整个图片变的生动起来。

经过用Lib上Kontext的改变后,
成了一头愤怒的狮子,
整体的色调,人物的服饰和装饰都没有改变,
只是把女孩变成了狮子并很好的融合成了一个新图。
雪佬脑洞下,如果这两张做个首尾帧,
视觉上一定是很震撼的。
把图中人物换成一头咆哮的狮子,但服装、帽子和配饰保留原样。原图的构图、色调和风格保持不变。

将她手中的饮料瓶换成了可口可乐。
试想一下,等Lib的Kontext开放多图上传后,
一秒穿越童话世界,不是梦,
想要什么效果,还不是你的(脑洞)说了算。
将图片上的饮料瓶子改成玻璃瓶可口可乐,图片中的中国女孩改成真实的人物,拥有真实人物的皮肤和头发质感,脸上不要酒窝,其他和原图保持不变


将图片中的背景换成马尔代夫,其他保持不变。
如下图:

将背景换成月球基地,图片中的人物坐在月球车引擎盖上,人物保持不变,注意人物和车的比例要合理,高清。
看看效果怎么样,

将背景设置在中世纪城镇上方,下方是小城镇的地景。在图像中,一个人骑在一条巨大的龙上。保持人物与原始图像相同,具有清晰的特征。注意人物和巨龙之间的比例。巨龙应该有详细和逼真的皮肤纹理,图像应该是高分辨率的。
也完全不用担心人物的一致性问题,
作为AI创作者来说,一致性是一直以来的痛点,
有了Kontext的加持,
这一切,就这样神奇般的解决了。

将参考图片输出为正视图、侧视图、后视图。
你怎么搞多参生图?
喏,就是这样,
如下图:

还是用咱们的Kontext模型,
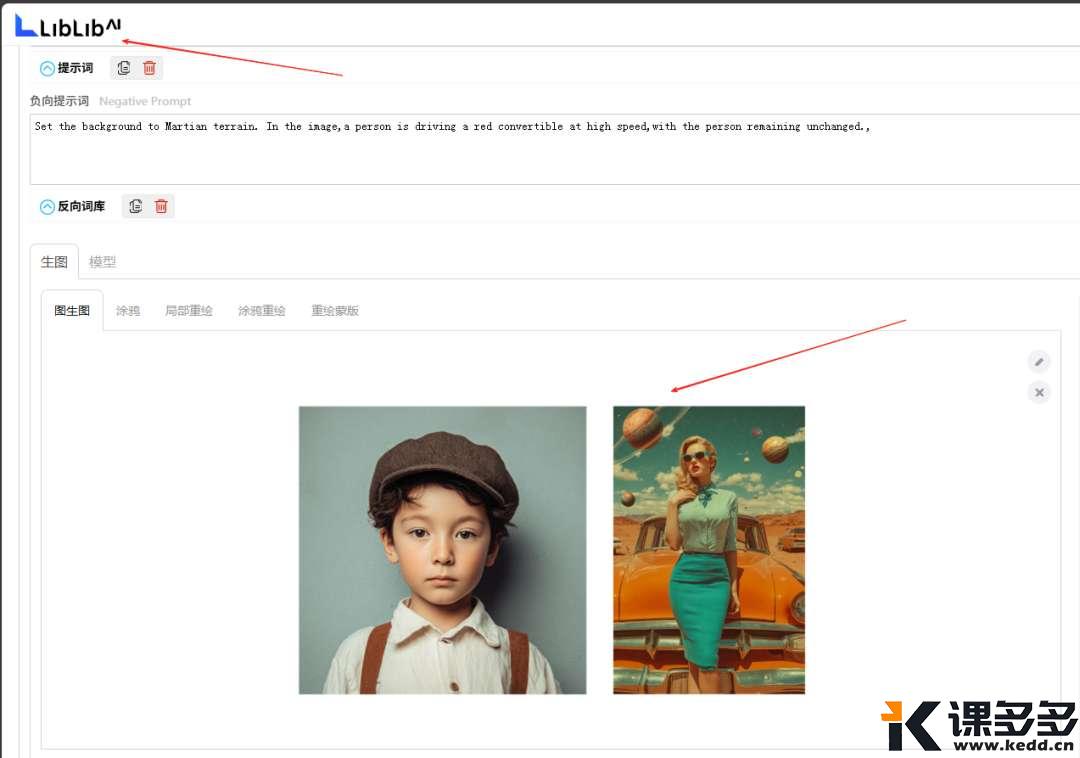
右边的美女搂着左边的小男孩站在一辆汽车前面,人物和汽车样式参考图片保持一致。
“duang”的一下,
如下图,就成了。

(值不值得一键三连,谢谢各位老爷们)
有了这个多参生图的骚操作,
那,想象空间可就大了,
可以做很多大胆的尝试了,
(尽管雪佬以前的文章里也写过很多,
但是我觉得Kontext模型的一致性,
是能够成为王者的。)
咱们趁雪佬这股热血直冲天灵盖的当口,
赶紧在测试一个,
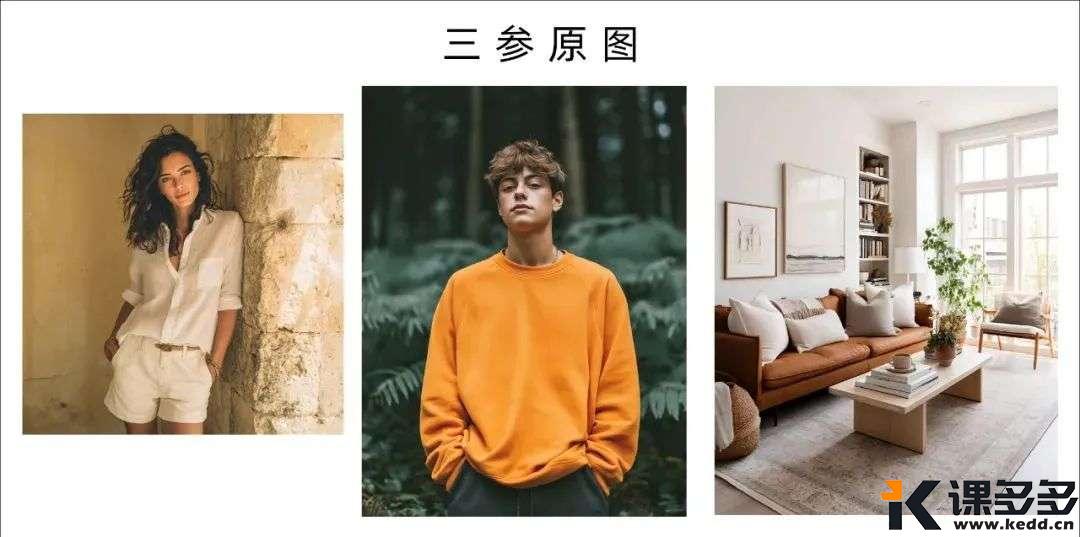
江湖规矩,咱们先上原图,

左边的美女穿着蓝色蓬松的服装,坐在右边的沙发上,形状与原始图片相同。

哪里想换点哪里,妈妈再也不用担心我的那啥
有了Lib 上的Kontext,
果然是可以为所欲为的。
还是先上原图,

右边的美女拿着左边的一个很小瓶产品,站在右边的场景中,美女和产品要保持一致,注意产品的比例。

也解决了,
电商场景也能轻松驾驭了。
完美。
看看Kontext模型能不能完美搞定,
首先,还是先上原图,
3 2 1
上成品图。
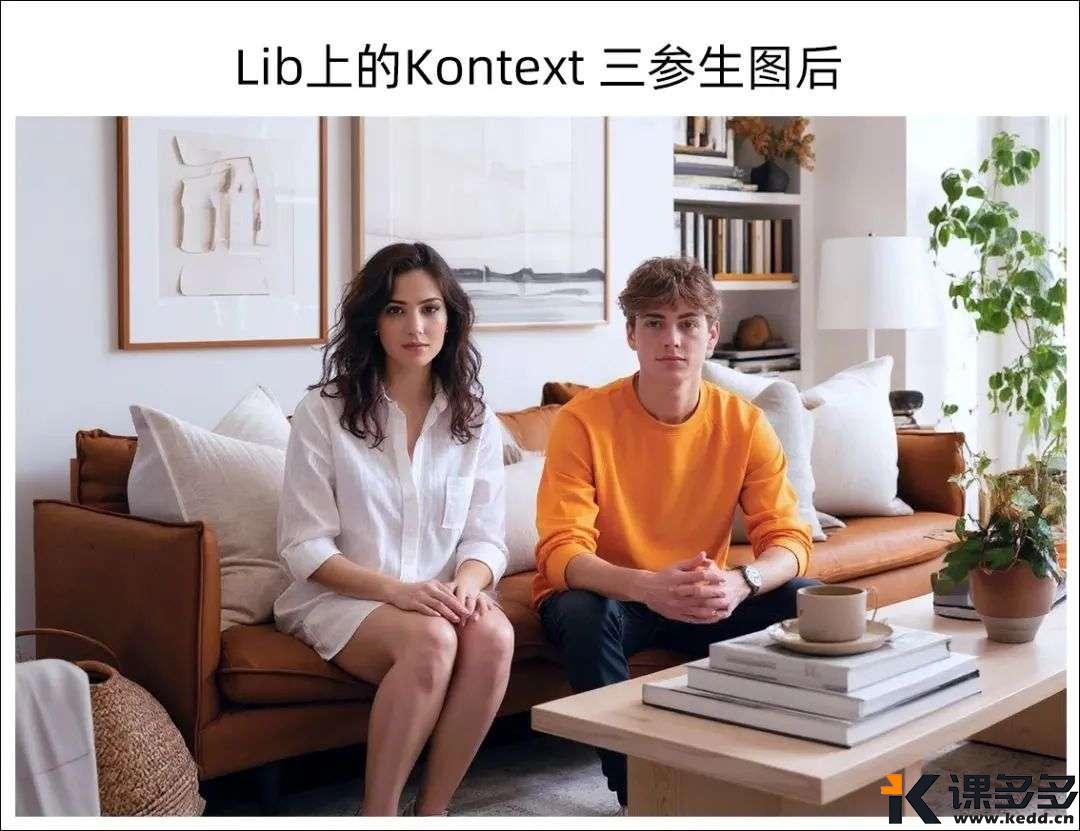
这也进一步证明了,
雪佬的脑洞是可行的,
所以,回头咱们测测四参?
(暗示一键三连,你的支持是雪佬创作的动力)
篇幅有限,
咱们今天就测试这么多,
更多脑洞玩法交给各位观众老爷去探索,
雪佬在测试过程中也感觉到,
Kontext的角色一致性真的是相当强,
提示词的精准书写,和模型的能力同样重要。
而且相应速度很快,
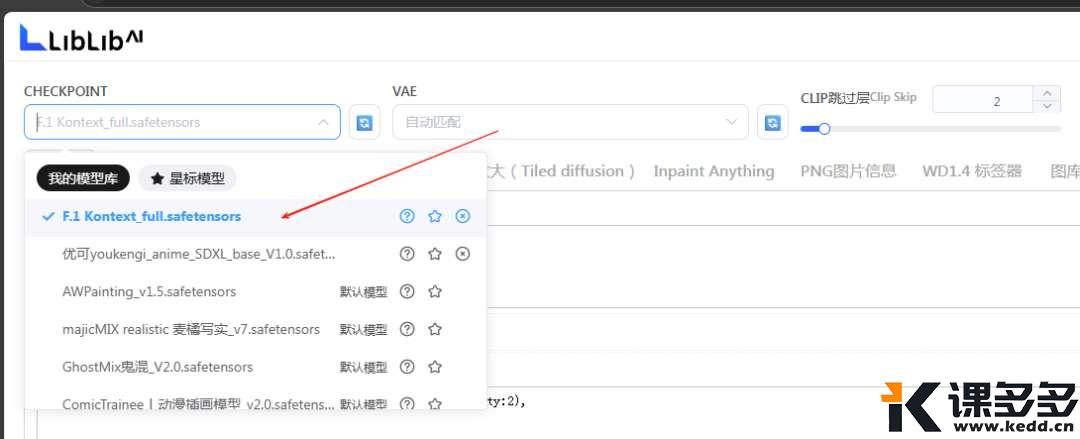
🔘说到在ComfyUI里调用
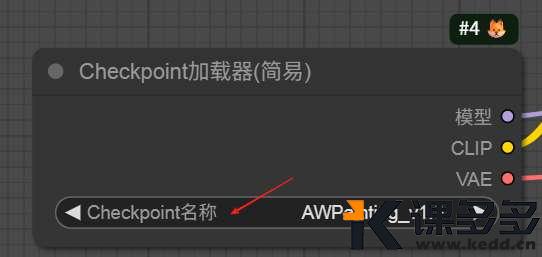
那么Lib也提供了很多成型的Kontext工作流,
帮你一键搞定你想要的图片效果。
有的观众老爷会问了:
那么这么好的工作流,在哪里能找得到,
别眨眼,雪佬这就给你演示,
打开之后如下图:

点击上面的工作流按钮,
可以看到,Kontext 有很多工作流。
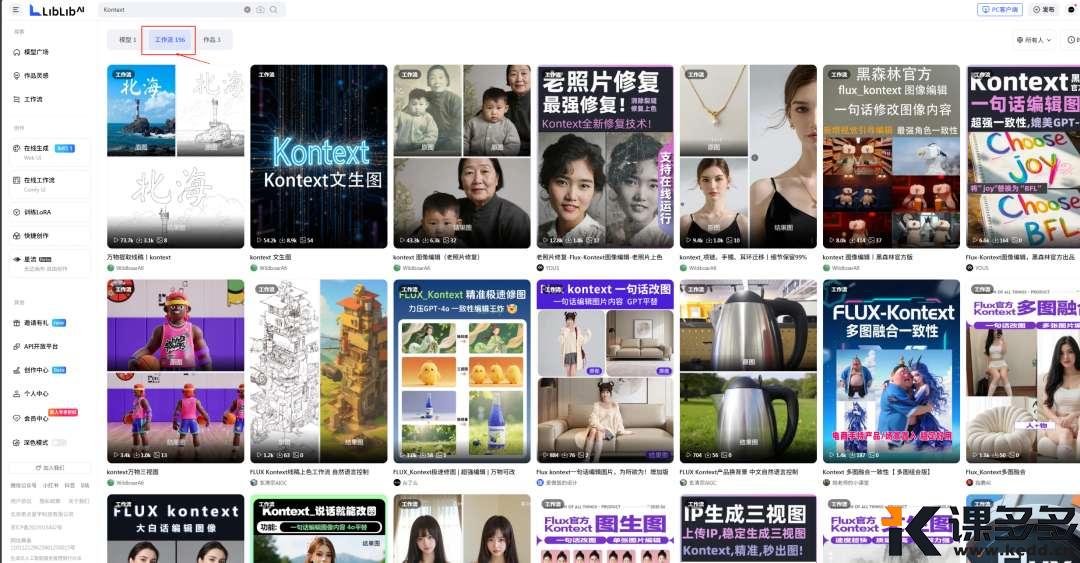
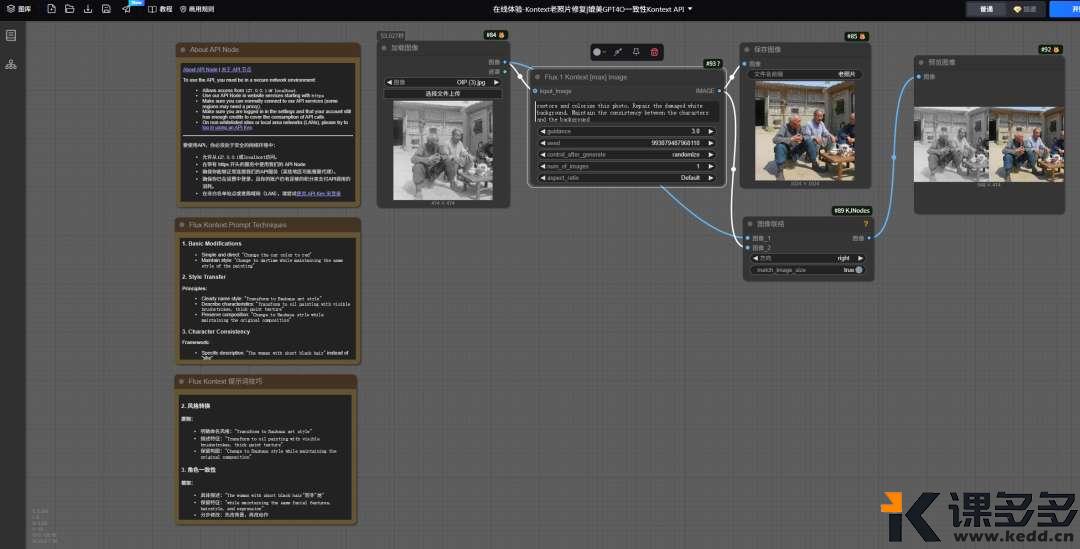
1、 左侧三个大框是信息提示节点

比如“改变物体颜色”、“转换绘画风格”、“保持角色一致性”等。
这是非常有用的参考。
作用: 这是整个工作流的引擎。它接收您的图片和文字指令,并执行所有的AI计算。如下图显示:
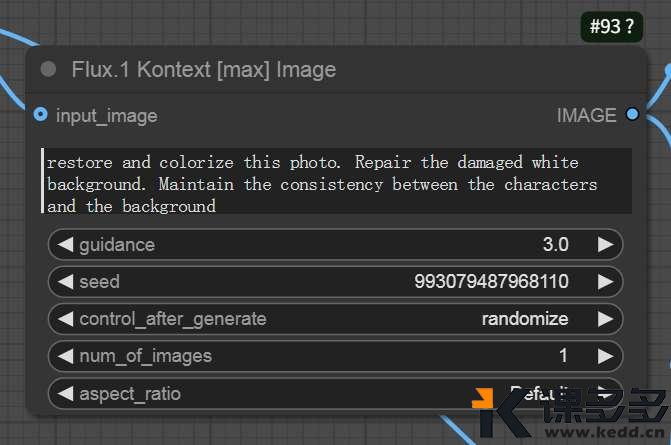
你可以给图像起个文件名,
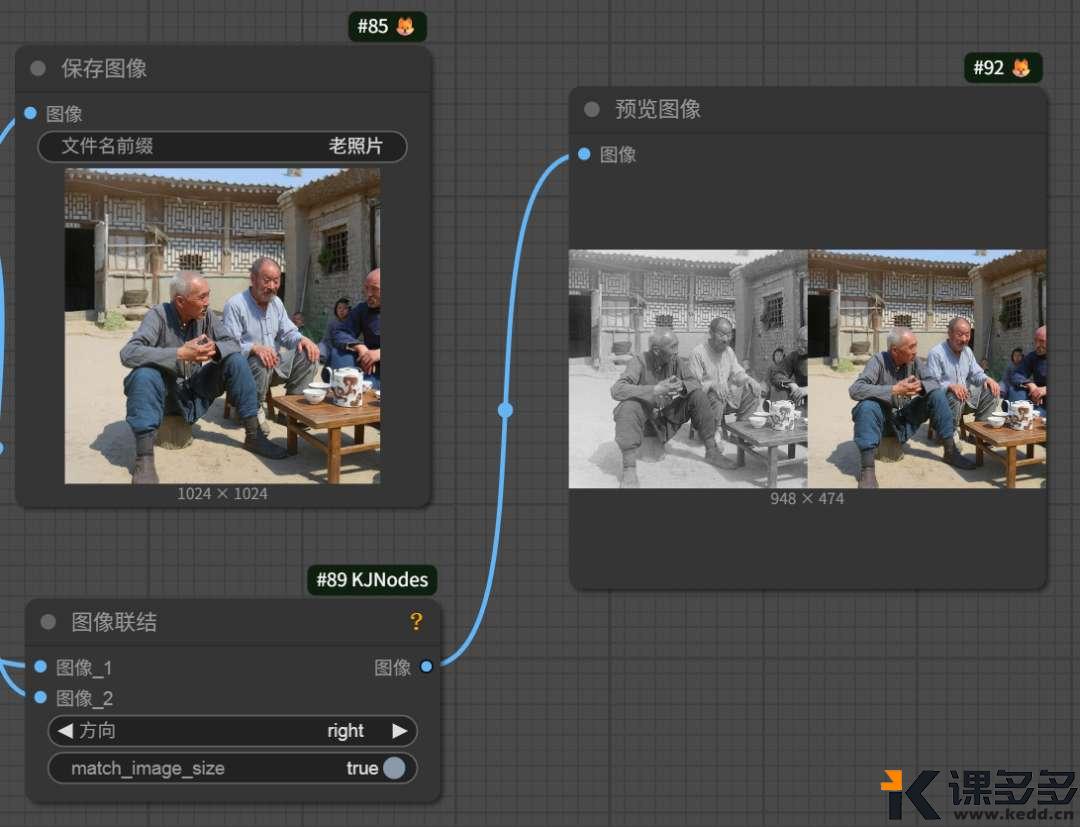
预览图像这里它很贴心的
把原图和生成后的图片并排放在这里,
让你能够很直观的看到变化。
你可以生成一个,
根据生成的图片质量,
再进行数值调整,
好了,以上就是工作流的使用方法。
🔘又双叒叕更新了,
🔘他们上了Kontext的多图参考功能,
🔘当当当当,
🔘3 2 1截图如下,
🔘这里注意下,是在文生图这个界面,
🔘提供了两种方式上传,
🔘一种是图库上传,(就是你在Lib的图库)
🔘另一种是本地上传(就是你的电脑)
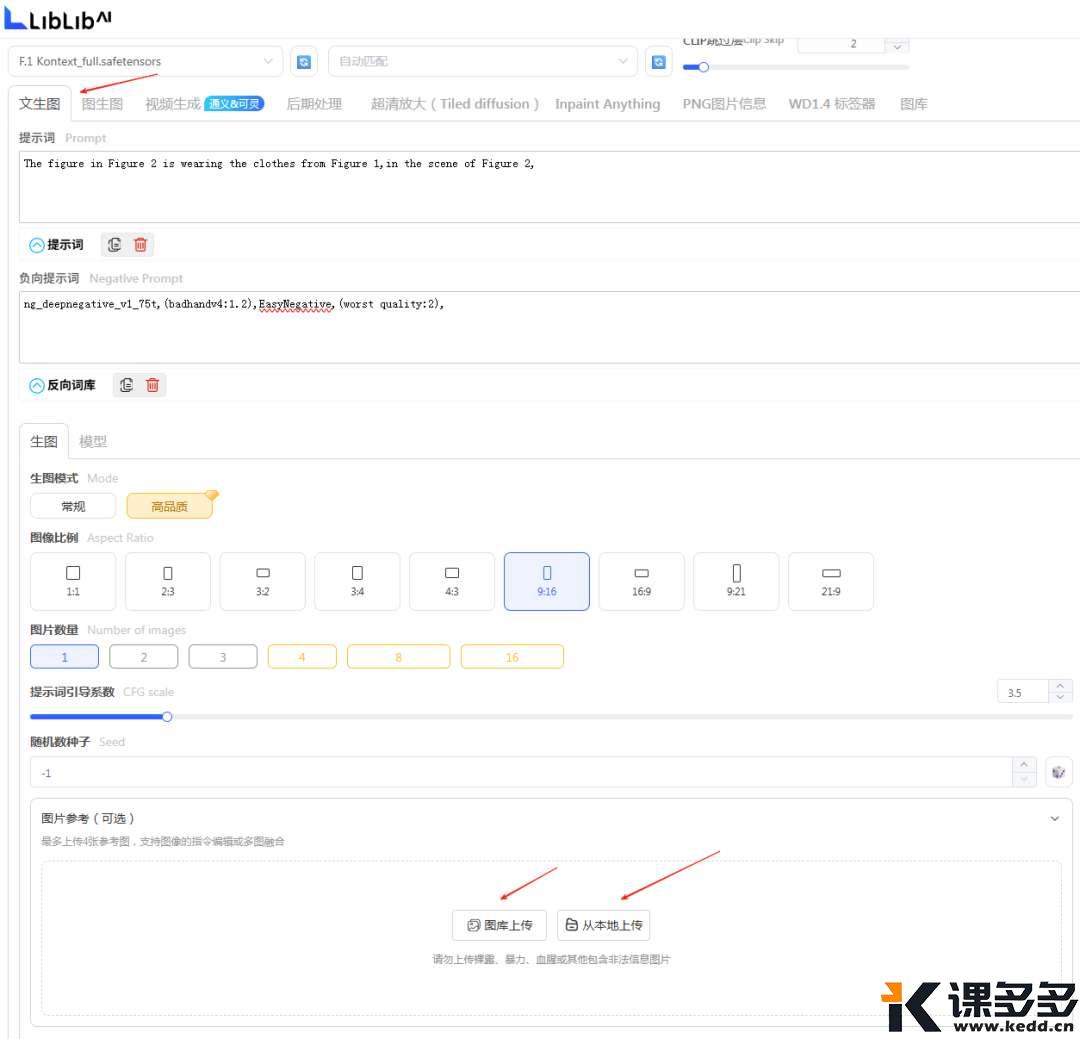
图片参考这里
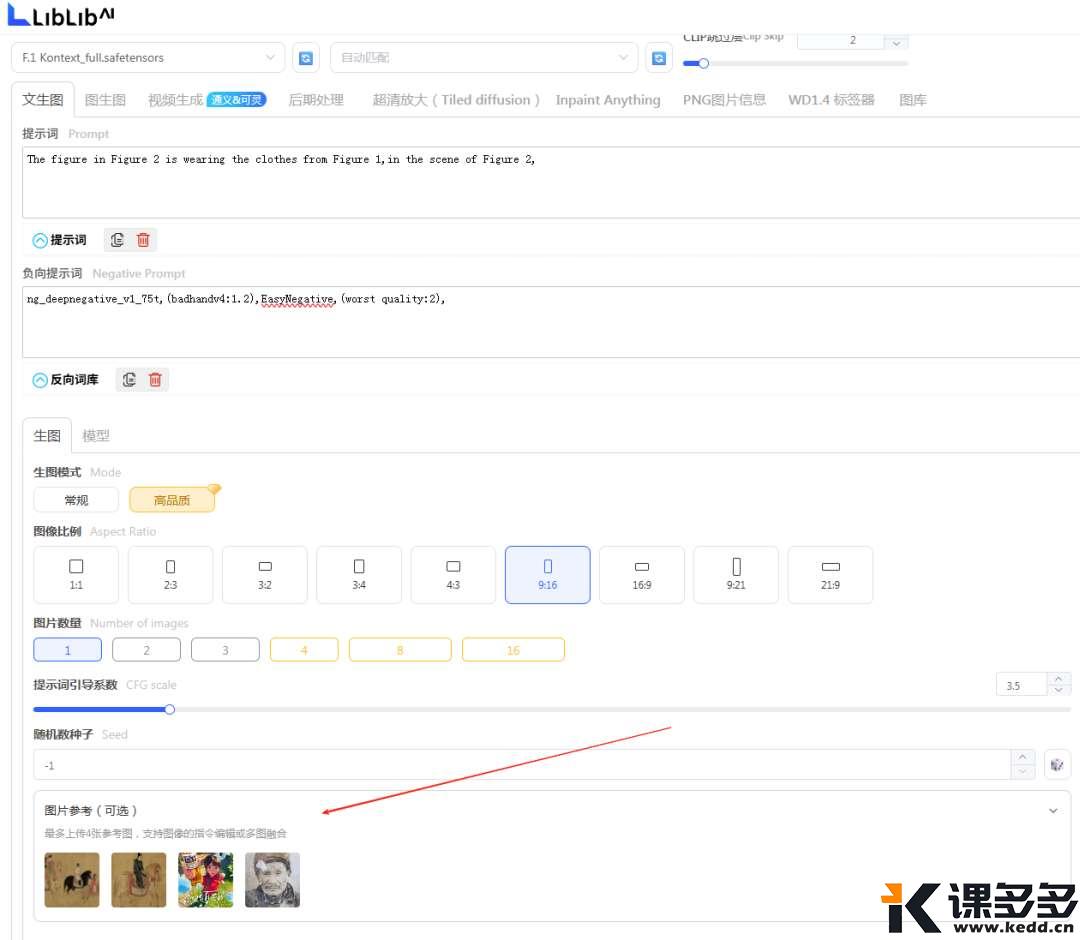
其他步骤,跟我文章最开始的图生图没区别,
这里提醒两点注意事项:
单图,是在图生图里操作,
多图参考,是在文生图里操作。
🔘而是深度的融入到Lib平台已有的创作系统中,
🔘所以对于作为创作者的我来说,
🔘用起来会省心和方便很多。
3、模特由正视图改成侧视图,风格不变。
4、一句话转变吉卜力风格。
5、一句话修改图片文字和人物服饰,以及动作。
6、一句话,美女变狮子,服饰场景不变。
7、3D动漫人物变真实人物,场景不变。
8、文字风格迁移,给一张参考图,一键快速迁移同款风格字体。
9、人物换背景,各种场景全掌控,图像不崩坏,颜色不泛黄,细节高度还原。
10、3D动漫人物三视图。
11、二张图片多参测试,三张图片多参设置。
12、Kontext工作流的调用和使用方法。
13、Lib Kontext模型上线多图参考功能。
https://www.liblib.art好了,
以上就是今天的全部内容,咱们下一篇见。






暂无评论内容