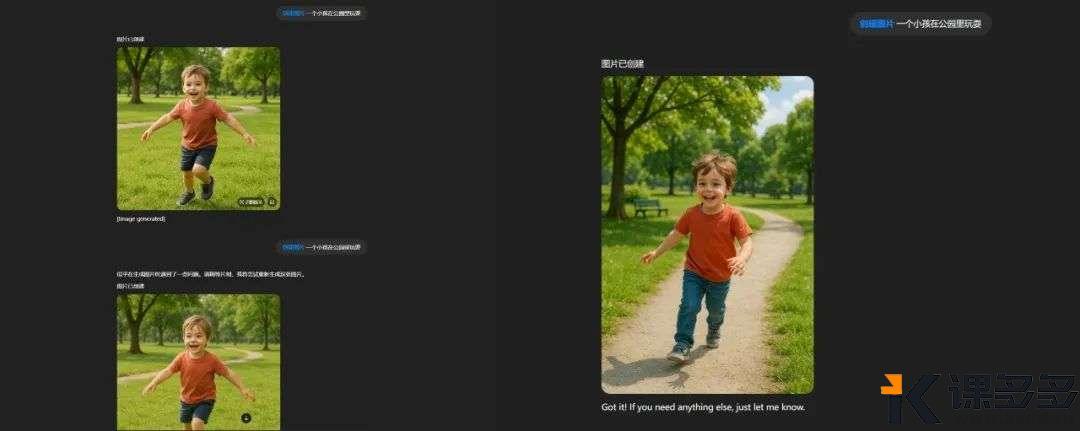
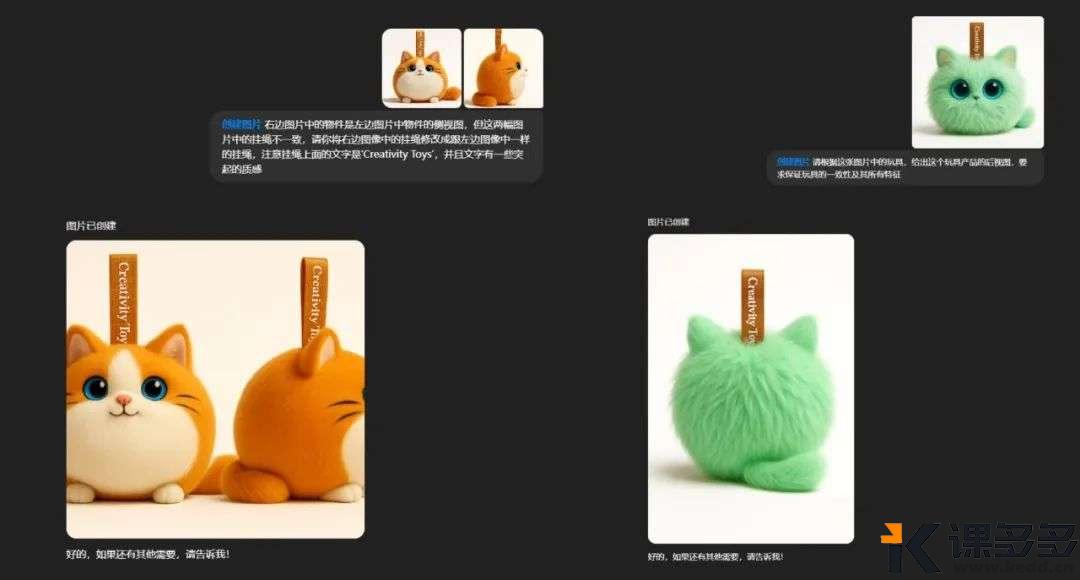
狂肝了十天GPT 4o,我发现了几点不足课多多1年前发布05812 在上一篇文章中,我们演示了4o高质量的图像、文字能力以及能让每个人动动键盘就可以成为设计师的图像编辑能力,但在文末我也同样提到,它并不是完美无缺的,也存在一些需要改进的地方,就比如… 呃…哈哈哈哈,皮了一下,让我们回归主题: 接下来,我将以自己最近使用4o下来的体验,阐述我觉得需要迭代改进,同样也是我最关注的几点,它们分别是: 同一提示词下的画面单一,缺乏泛化性 输出图像尺寸的局限性及匹配不稳定 对于主体甚至是场景缺乏强控制力 首先,我们先来看第一点:同一提示词下的画面单一,缺乏泛化性。 具体什么意思呢?就是在我的使用体验中,发现使用同一段提示词无论让4o跑几遍,出来的画面内容及结构近乎一致,比如我拿上一篇文章中的第一个例子来说,提示词是一位60岁女人的面部写真,然后我就用这同一段提示词跑了好几次,好家伙,出来的画面不能说完全一样吧,但这咋一看也太像了吧 直接给我干出六姐妹… 看到这样的结果,我开始思考是不是因为提示词的原因,会不会【一位60岁女人的面部写真】就几乎把画面控死了,不管是在性别(女)、年龄(可以对应到皮肤特征)、图像类型风格(写真),甚至是构图方面(面部),貌似留给AI自由发挥的余地已经不多了 于是,我开始修改提示词,这次为:【请为我绘制一幅图像,画面中是一名老者的全身展示】,其中,没有对性别和场景的限制,全身展示也释放了AI对姿态的无限探索。 但正如上图展示的,即便是我更换了对于AI来说更自由更友好的提示词,结果貌似也还是如我所想的,输出的图片依旧存在高度的相似性,或许应该用一个更贴切的词——过拟合 好吧我必须再次停下来认真思考,我也确实想到了可能还存在的一点原因——GPT在同一对话界面中是存在很长的上下文长度的,也就意味着GPT在接下来的每一次内容输出过程中,都会对前文的内容进行参照,而图像自然也在其参阅范围当中。 基于此思考,我麻溜得新建了好几个不同的对话界面 然后直接将上面提及到的两段提示词原封不动地扔给它们,好家伙,结果简直…依旧大失所望… 但我还是测试了其他提示词,不难看出,右边新建对话界面后输出的图像自动变成了竖构图,因为4o的生图展示是一个类加噪降噪的过程,所以我们会先看到一张图幅比例已经确定的模糊图像 不可否认的是,当我看到其突然变成竖构图时心里还有点小惊讶,还以为会有什么变化,但当最后的图像出来后,好吧,还是那个味儿~ 这时候,我已经开始想念我的其他AI朋友了(以下图像由MJ V7生成) 所以,我认为这是GPT需要改进的一个很大的点,同一提示词下画面的单一势必会带来使用的枯燥和灵感的局限,而AI的泛化与不确定性本就是其迷人的一部分 接着,我们来聊聊GPT的第二个缺陷:输出图像尺寸的局限性及匹配不稳定 如果大家已经体验过4o的图像功能,相信也不难察觉到,不管是文生图还是图生图(以我们上传的图像作为参考或直接编辑),GPT在最终图像的输出尺寸方面,只有1024*1024(1:1)、1024*1536(2:3)、1536*1024(3:2)这三种 或许到这里有人要问了,这有什么问题吗?确实也没有什么大问题,只是…请看展示: 这多少有点硬塞的成分了,所以我认为根据实际的画面内容灵活得调节图幅比例,甚至是用户可以直接自定义图幅比例,就像MJ那样,或许会有更好的体验效果 另外,以上说的是关于4o输出图像的尺寸带来的局限性,那上面还提到的图幅匹配不稳定又是怎么一回事呢?看完以下画面或许你就懂了: 没错,不能说4o对于画面比例的匹配是完全随机的吧,但确实会经常出现这种乱来的情况…怎么说呢,就有时候,确实挺让人无奈的哈哈 最后,4o对于主体甚至是场景缺乏强控制力 在这里我只需要举一个例子就完全够用了,那便是我们在让4o为指定产品进行编辑操作时,它或多或少都会改变原先产品的样式,甚至有时候我们只需要调整某一个小区域,但最终出来的效果却是整个画面都进行了调整,就比如以下的玩具案例: 很明显,最终出来的结果与原先的产品外观几乎已完全不同…我甚至还在提示词中专门强调了要保持一致性… 好了以上便是我着重关注的4o几点需要改进的地方,但不管怎么说,这次的4o所带来的惊艳是远大于不足,在我看来,虽说现阶段这个代表地球最强的多模态大模型还存在着一定的不稳定和局限性,但这毕竟也只是将LLM(大语言模型)与图像编辑功能高度整合的初代产物,至少在当下,已经为各大AI大模型厂商指明了方向,相信在未来不久,市面上的各大主流模型也会紧跟脚步,到那时候,模型对于图像的编辑能力,也必将有一个质的飞跃! © 版权声明文章版权归作者所有,未经允许请勿转载。THE ENDAI笔记 喜欢就支持一下吧点赞12 分享QQ空间微博QQ好友海报分享复制链接







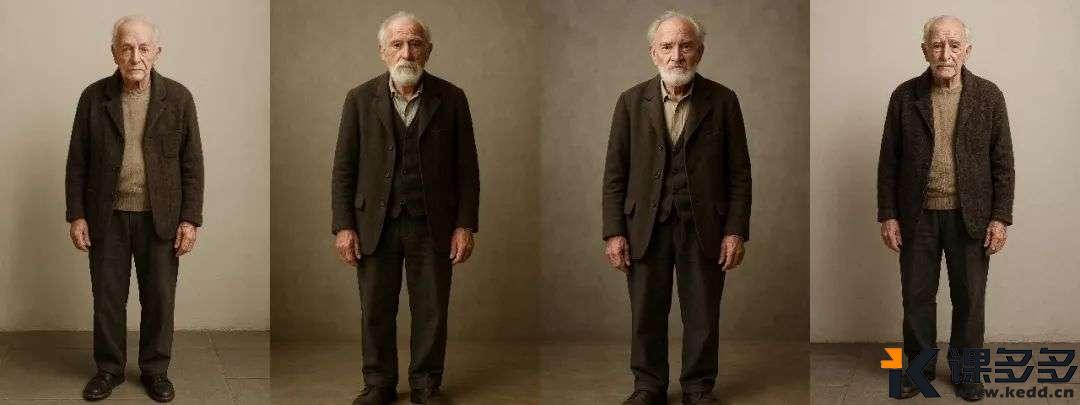







暂无评论内容