前几天,Vidu发布了新功能,体验下来确实丝滑,我当时立马写了篇《中国视频 AI 再出第一》给大家推荐了一番
结果有朋友留言说,Vidu的效果和某些开源模型差不多,二流
哈哈,第一,Vidu 效果并不差,第二,可不要小瞧了开源!
有这么一款国产AI视频,不仅开源,而且强大,甚至能根据视频内容自动生成音效!
它就是阿里巴巴的通义万象!一款开源的视频生成模型,基于主流的 DiT 和线性噪声轨迹 Flow Matching 范式
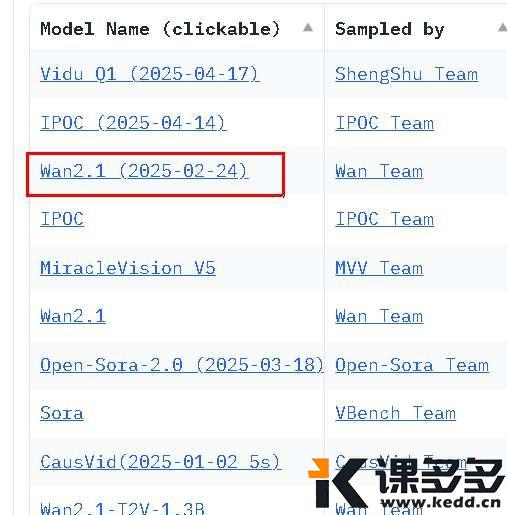
通义万象目前在国际权威视频生成模型排行榜 VBench 上名列第三,一度超越Sora!
我在《甜炸!AI让景甜变身吉卜力女主,这纯欲漫感谁顶得住?》介绍过通义万象
今天,就让我带大家再深入了解一下,看看它的实际效果如何
注意听,视频里美女踩在落叶上的沙沙声、林间的鸟鸣,这些音效都是AI自动配置的,相当巴适!
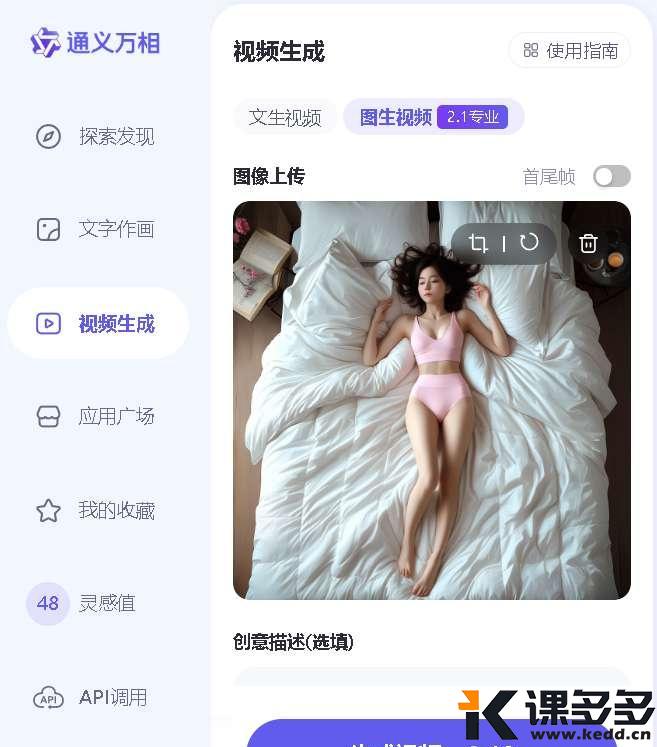
看看这个图生视频,尺度非常大!从图到视频都是通义万象做的,后文我具体讲怎么弄
悄咪咪说一句,这张图给可灵、即梦都会报错!会因为太辣眼睛拒绝生成
那么,如此给力的通义万象该如何使用呢?
主要有两种方式:
第一,本地部署
如果你是技术大佬,可以尝试部署到自己电脑上。具体教程可以参考这篇文章《通义万相2.1(Wan2.1)安装与操作全指南》。
不过要注意,本地部署对硬件尤其是显卡有一定要求,显存至少需要16GB;本地部署优点是你想生成啥都没问题
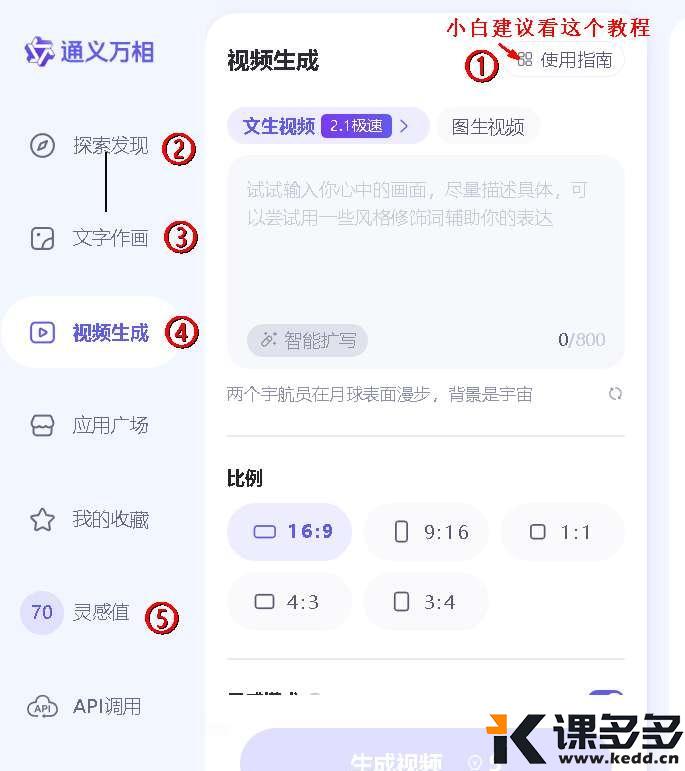
对于大多数朋友来说,直接访问官网免费体验是最方便快捷的方式!
网址:tongyi.aliyun.com/wanxiang
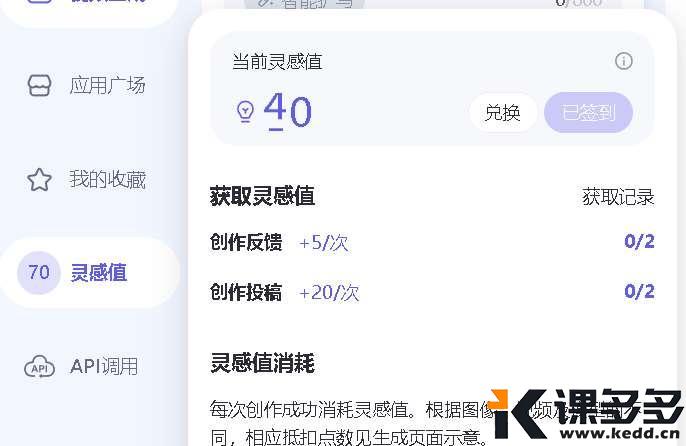
⑤ 灵感值:这是“燃料”,每天会自动赠送50点,签到还能额外获得20点。生成1张图片消耗1点,1个视频消耗5-10点
②探索发现:这里汇集了其他用户的优秀作品,可以找找灵感
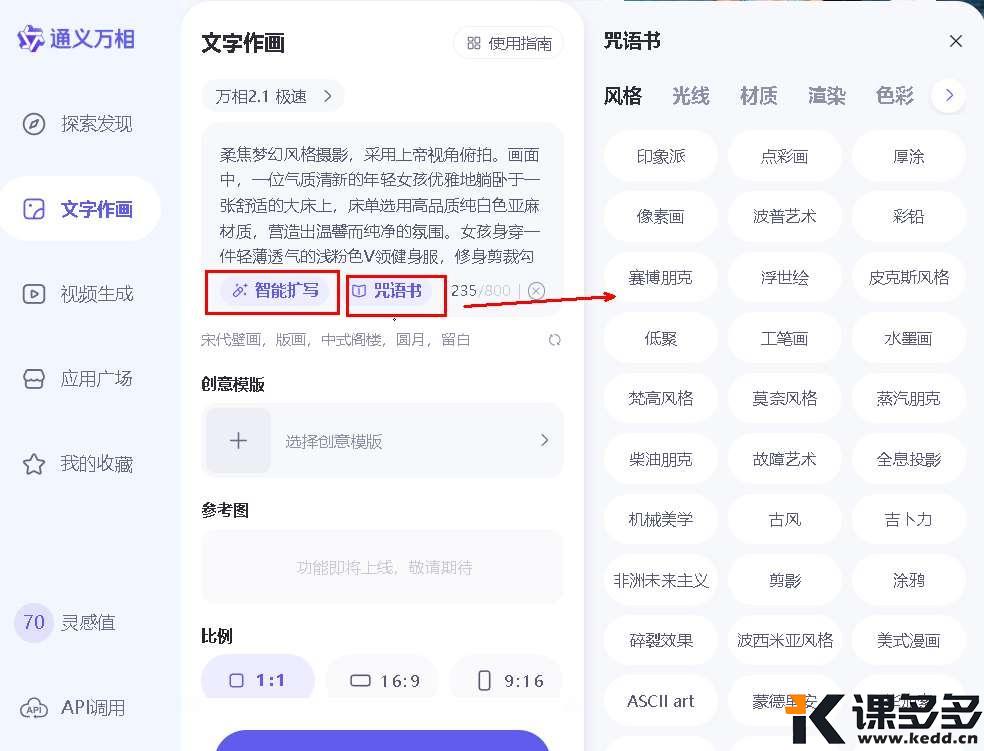
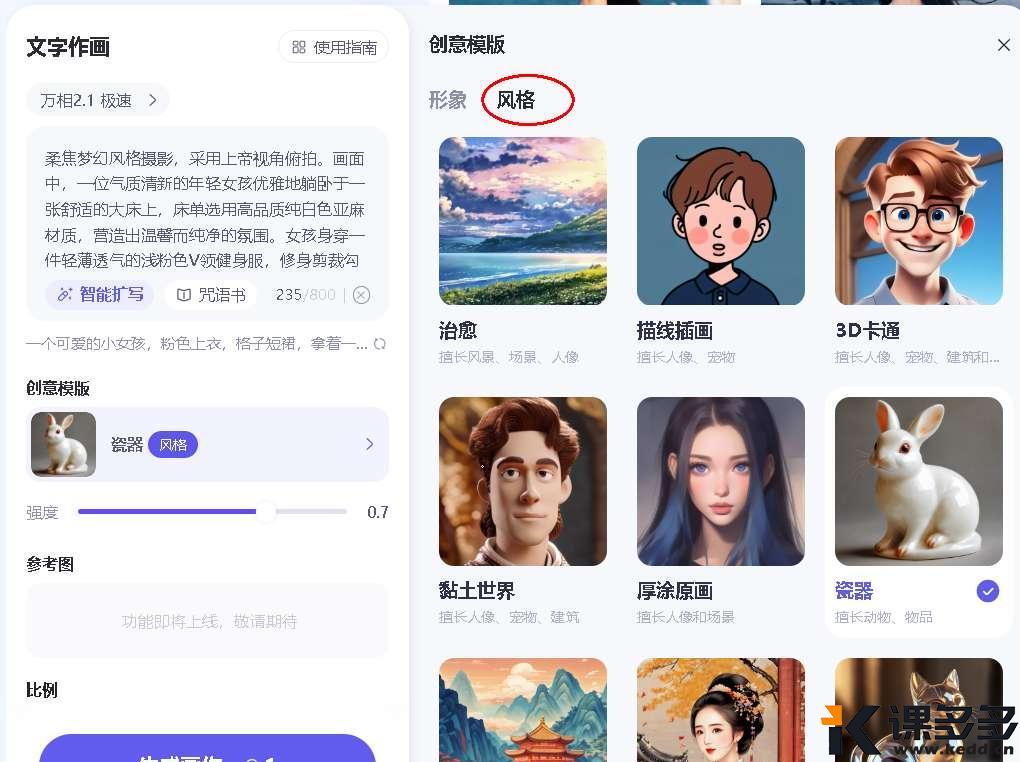
有两个选项:智能扩写,咒语书(模版),新手友好。输入几个关键词,点击“智能扩写”,它就能帮你生成一段详尽的提示词
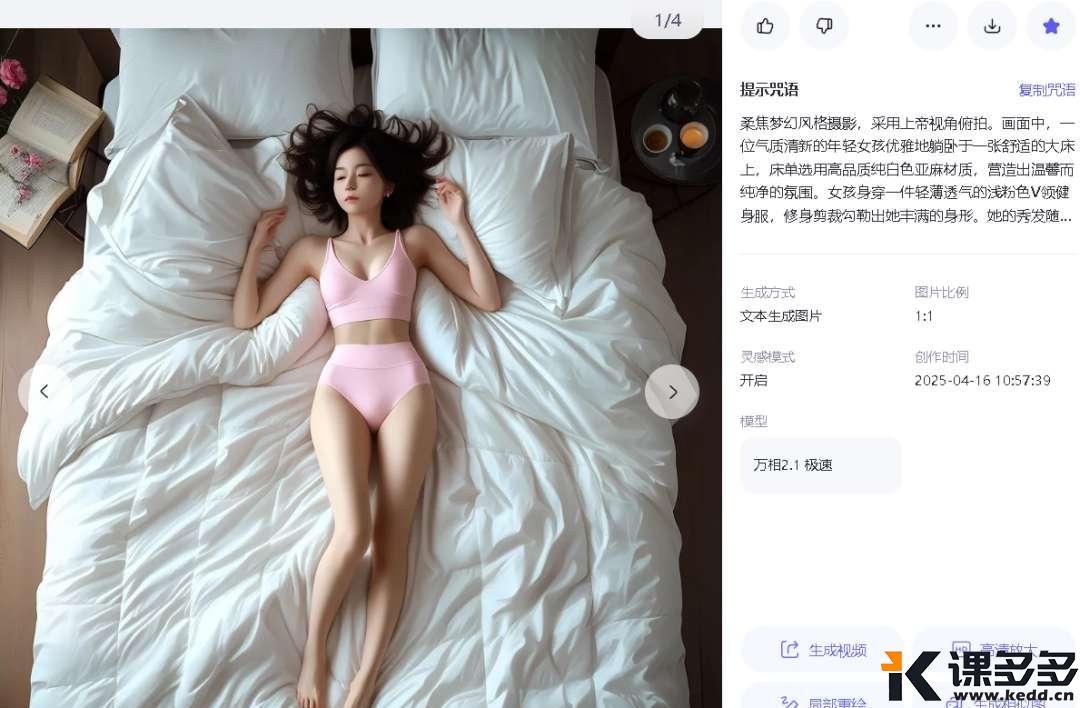
输入提示词:“柔焦梦幻风格摄影,采用上帝视角俯拍。画面中,一位气质清新的年轻女孩优雅地躺卧于一张舒适的大床上,床单选用高品质纯白色亚麻材质,营造出温馨而纯净的氛围。女孩身穿一件轻薄透气的浅粉色V领健身服,修身剪裁勾勒出她丰满的身形。她的秀发随意散落在枕头上,面部表情放松而恬静,仿佛正沉浸在一场美妙的梦境之中。床边散落着几本翻阅过的书籍和一杯未饮尽的花草茶,透露出一丝文艺气息。光线柔和而均匀地洒在房间内,营造出一种宁静而私密的空间感。整体构图采用对角线布局,使画面更具动感与层次感。”
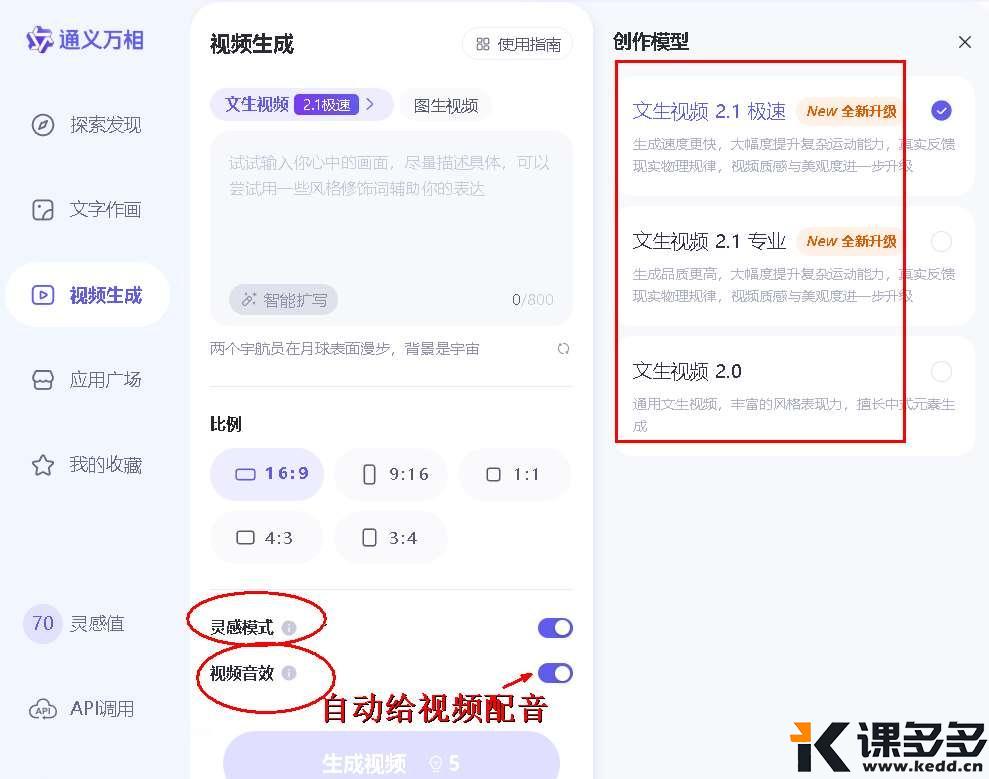
核心功能,分为图生视频(i2v)、文字生视频(t2v)
支持扩写提示词、比例、灵感模式(增加创意灵感,提升画面丰富度与表现力,)、视频音效(打开自动给视频配音)
我们以上面生成的图片为例,希望画面中的女孩打个哈欠,再翻个身
输入简单的动作提示:“女孩打哈欠,翻身”,并确保打开“视频音效”选项
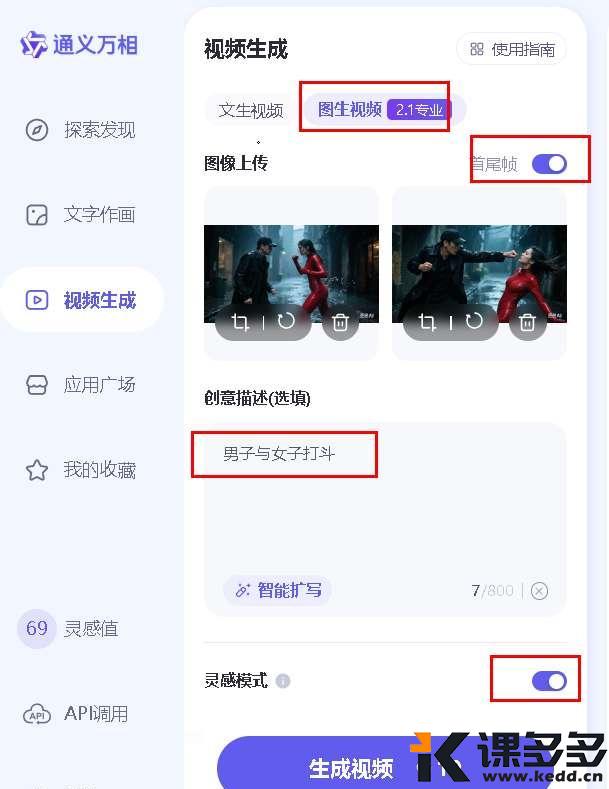
通义万象还支持一个很实用的功能——首尾帧生成。你可以上传两张图片作为视频的起始帧和结束帧,AI会自动在中间进行过渡和动态演绎。
例如,我们用之前豆包生成的一套“暴雨夜动作戏”电影分镜中的两张作为首尾帧:
小技巧:如果你有一系列分镜图,比如12张,你可以先用第1张和第2张作为首尾帧生成一个短视频,再用第2张和第3张生成下一个,以此类推。这样,12张分镜就能串联成一个大约1分钟的连贯视频了!
切换到“文生视频”界面,别忘了勾选“视频音效”,然后输入我们的提示词:
“纪实摄影风格,一位年轻女子沿着落叶覆盖的森林小径渐行渐远,她长发飘逸,乌黑顺直,浅色肌肤在自然光线下更显细腻。女子身着浅粉色长袖上衣,搭配紧身浅蓝打底裤与白色运动鞋,头发上点缀着简约白色发圈。她轻盈的步伐踏过泥泞小径,四周被光秃秃的树木和繁茂灌木包围,一片晚秋景象。绿色植被点缀其间,上方则是阴沉厚重的天空,营造出静谧而自然的氛围。中景,跟随女子背影的视角,展现她融入自然的和谐之美。”
得到视频如下,哇塞,这氛围感,是不是很有故事性?尤其这背影,引人遐想啊!
以上就是通义万象的一些基本操作和亮眼表现。
虽然在核心功能上与其他视频AI工具大同小异,但通义万象凭借其开源特性、智能音效、以及在某些创作上的较大尺度,依然展现出了自己独特的优势和魅力。
感兴趣的朋友冲鸭!不妨亲自去体验一下!









暂无评论内容