
那个谷歌,它带着全家桶鲨回来了!
看得我眼花缭乱,接下来就以最简洁的方法速看一下都有哪些惊喜。

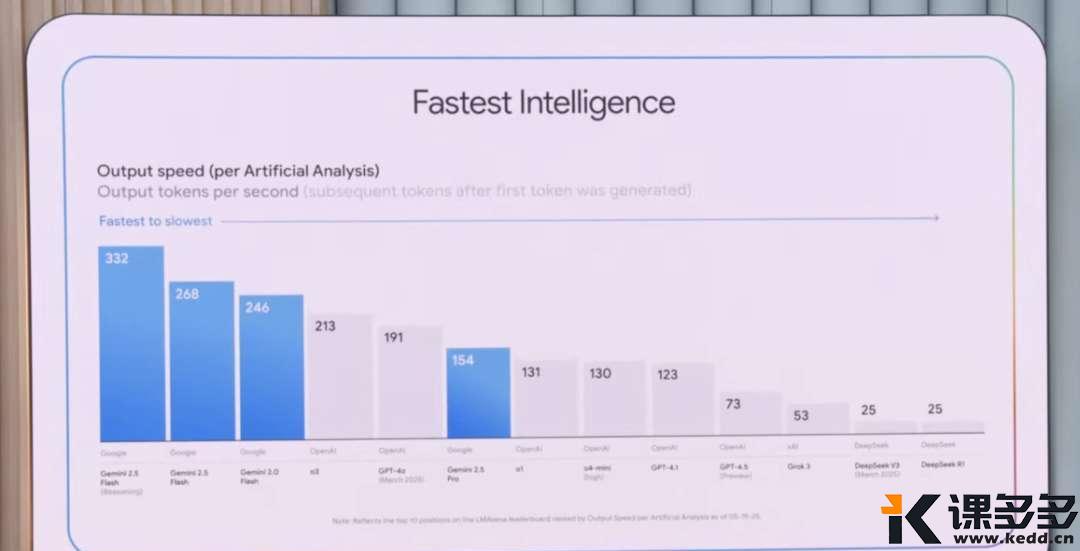
基础功能
AI视频通信
Google Beam 显示器上有6个摄像机对人实时摄影并变成3D的效果,跟他人视频的时候就能看到一个立体的人了。
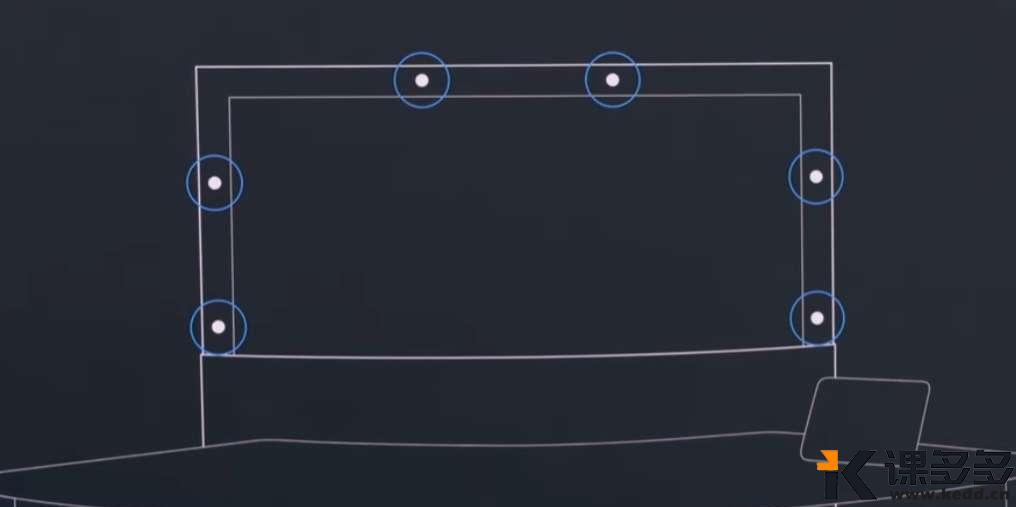
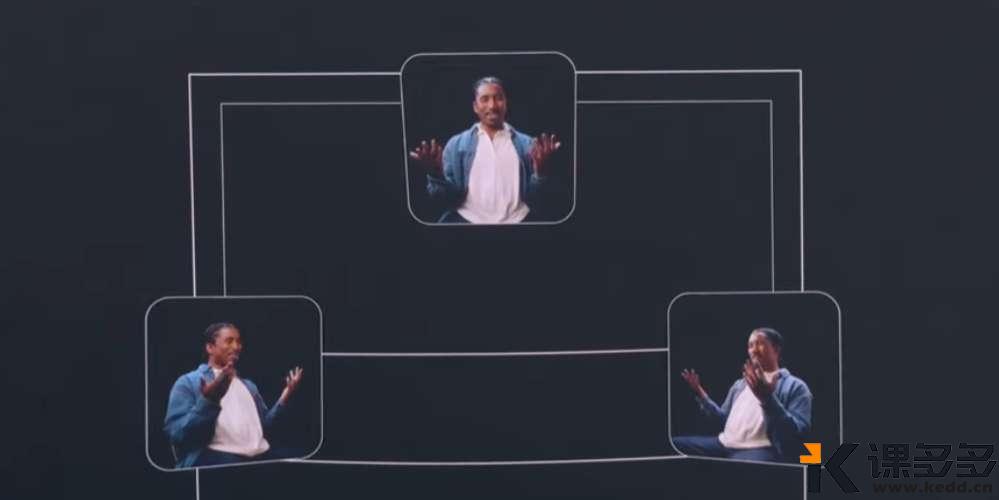

惠普目前已经与谷歌合作,几周后会公布。
实时语音对话翻译
Google meet 不仅可以模仿说话的声音还有语气。
前支持英语和西班牙语之间互译,后续会继续更新其他国家的语言。
AI实时视频对话
Gemini live AI睁开眼睛了,可以看到实时画面,并回答提问者的问题。

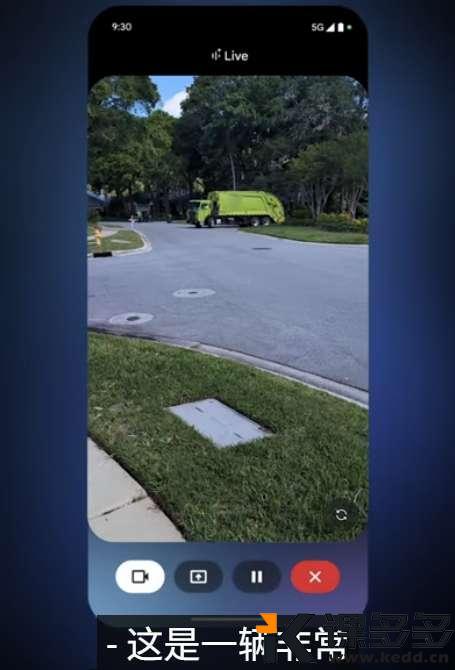
目前安卓和IOS都可以用这个功能了。
Agent+MCP
常见的Agent功能
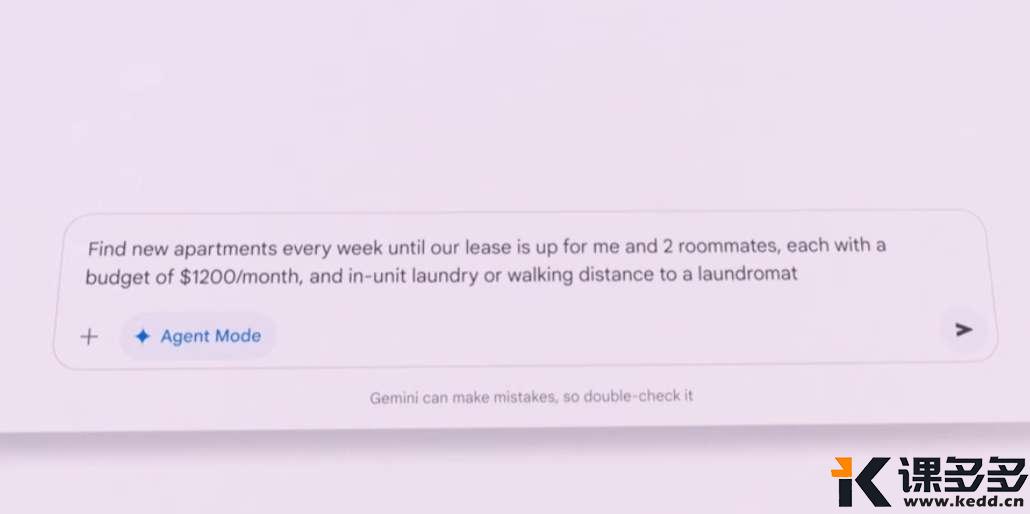
目前 Agent Mode 只能付费使用。
牛得不行不行的个性化模式
案例:你给别人回复邮件,想半天只能蹦出来几句话👇

但是AI会在你以往的各种信息(邮件、文件、资料)里找到关于你的资料,并模仿你的语气说话方式直接优化内容。
文本转语音
案例:正常说话转气声,英文转其他语言,效果非常丝滑。
今天就能用了,API还得等一阵子。

超强编码能力
它能理解复杂的内容(文字+图片),并帮你直接改代码。
案例:我现在有一堆去博物馆拍的照片,想要把照片围成一个3D的球体。
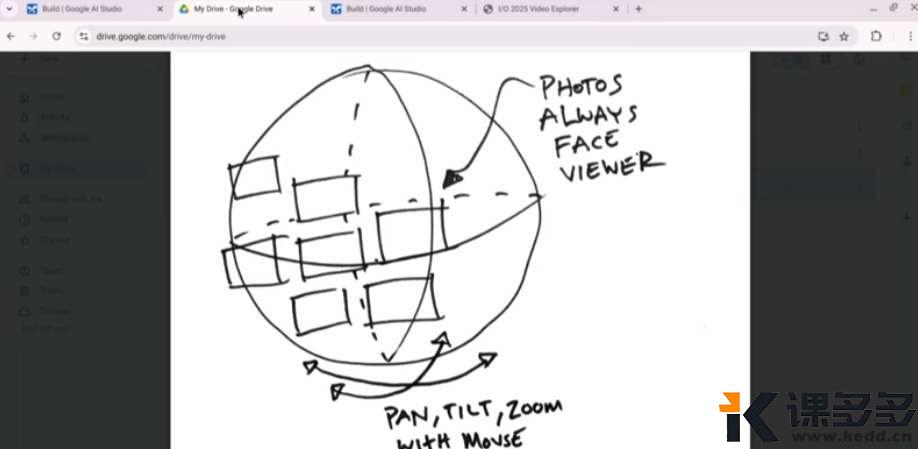
给对应的草图和提示词,2.5 pro开始自动调整代码。
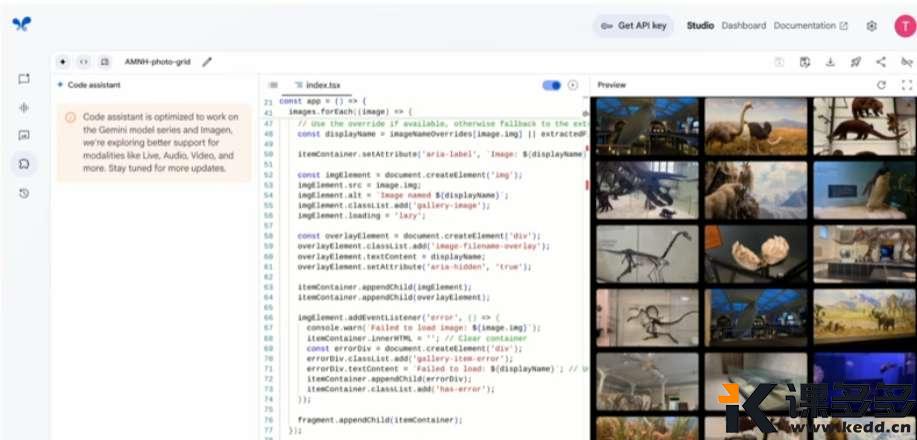
最后成品
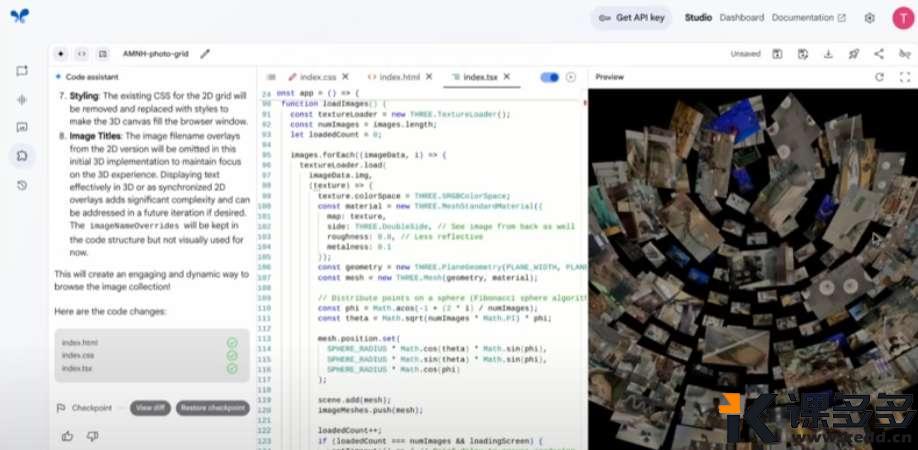
选择其中一张照片,还可以对这张照片进行提问,AI会用语音来回答。

这个功能可以说是产品经理狂喜了,现在就可以自己手搓APP。
Gemini功能更新
Deep Research 分析工具
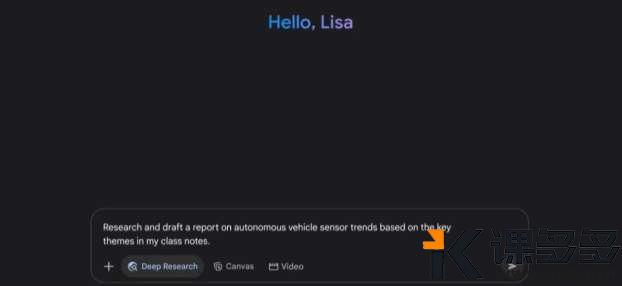
现在能直接上传文件和图片,像 PDF、普通图片、Word 文档这些,拖到和 Gemini 的对话框里就行,它就能理解这些内容,还能做总结、对比。
另外,以后它还能和 Gmail、Google Drive 一起用(不过这个功能还没正式上线)。
等能用的时候,只要你授权,Gemini 就能从你的邮件和云端硬盘里找数据,然后对比好多文档,给出特别智能的回答。
Canvas 内容生成
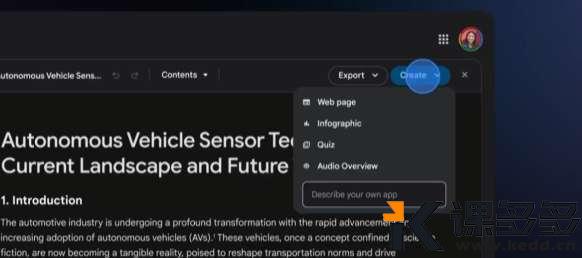
现在它多了个 “Create” 按钮,以前创作得费劲输入提示词,现在不用了,直接根据当下的聊天内容,就能自动生成互动内容。
而且,它还能把 Deep Research 分析出来的结果,一键变成网页、播客音频、互动测验这些不同的形式。
不管你是做营销的,想弄点宣传网页;还是当老师的,想把教学资料变成播客;又或是自媒体人,想搞些互动测验来吸引粉丝,用它都超合适,能省不少事儿。
Gemini for Chrome-AI插件
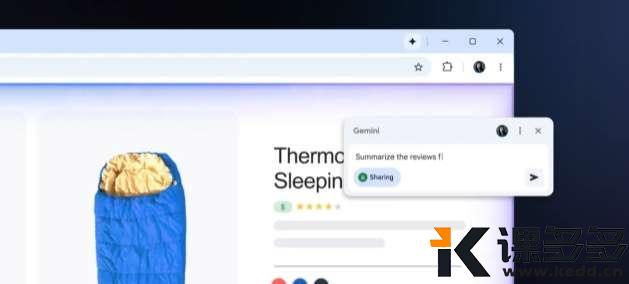
谷歌把 Gemini 集成到 Chrome 浏览器,总之就是浏览助手。
任何网页点 Gemini 图标,打字或说话就能提问,能总结网页、解释术语、跨页问答,不用来回切标签页,再也不怕标签页乱成一团。
这功能先给美国桌面版 Gemini 订阅用户用。
Imagen 4-AI生图

推出了 Imagen 4 这个升级版的图像生成模型。
细节特别清晰、特别细腻,就跟拿放大镜看似的,每一处都清清楚楚。色彩也特别自然、特别丰富,看着特别舒服。而且生成的文字和标注也更靠谱了,不会出现乱七八糟的情况。不管是人物的脸,还是衣服上的纹理,又或者是背景的构图,视觉效果都比以前强太多了,简直上了好几个台阶!
现在,只要你是 Gemini 的用户,不用额外花钱订阅,就能免费薅一把。




暂无评论内容