
总觉得自己问AI的时候拿不到心仪的答案?
那你可以考虑学一下提示词的写法。
最近谷歌官方出了一个提示词的白皮书,内容很长,而且是全英文的。

我把核心的两大块内容提取出来(主要满足日常办公学习),并用大白话讲一遍。
把这篇文章从头到尾看一遍,你能对大语言模型有初步的了解,并且学会基础的提示词写法。
废话不多说,现在就开始吧。
一、认识大型语言模型
大语言模型(LLM)就像一个学富五车但有时候会走神、需要你清晰引导的学生。它通过阅读海量的文字信息来学习,然后掌握词语之间的关系和模式。
LLM 的工作原理(猜词游戏)
你给LLM一句话作为开始(这就是输入),它就会根据自己学到的知识,预测接下来哪个词最可能出现在这里,然后把这个词写出来。
接着,它再根据前面所有已经写出来的文字,预测下一个最可能的词……就这样一个词一个词地“猜”下去,最终生成一段完整的文字(这就是输出)。
它猜得好不好,取决于它“学”得多不多,以及你的“指令”清不清晰。
提示词 (Prompt) 是什么
简单来说,提示词就是你给LLM的文字指令、问题或引导。
告诉LLM你想让它做什么,或者提供背景信息帮助它理解你的意图。
一个好的提示词就像是给那个“糊涂”学生的一份清晰的课堂任务单,让他知道目标是什么,需要怎么完成。
提示词工程有什么用
它是你掌控AI的关键!通过优化提示词,你可以让LLM更准确、更高效地完成各种任务,比如帮你写文章、做总结、翻译、编程、创意生成等等。
如果你给的提示词模棱两可或不够明确,LLM很可能会给你一个跑题、没用甚至奇奇怪怪的回答。
写出完美的提示词通常不是一步到位的,需要你像调教学生一样,不断尝试、修改、再尝试,这是一个持续优化的过程。
控制 LLM 的回答(简单设置)
LLM通常提供一些参数,可以调整它的输出风格。
-
回答的长度: 可以限制输出的字数或段落数。 -
回答的风格/变化(温度):
-
“温度”低: LLM会选择它认为最安全、最常见的词,回答倾向于保守、稳定,有点像教科书上的标准答案。 -
“温度”高: LLM会更“大胆”,敢于尝试一些不那么常见但可能有创意的词,回答会更活泼、多样,但也可能出现意外或跑偏的内容。
还有一些其他参数(如Top-K, Top-P),它们也是用来调节LLM选择词语时的“冒险”程度,影响输出的多样性。理解它们是用来调整AI“个性”的就行。
二、核心提示词技巧
1.零样本/一个样本/多个样本提示
这是最基本、最常用的一类提示方式,用来教语言模型“怎么做一件事”。
它们的区别在于:你给模型多少个示例(例子)?
① 零样本提示(Zero-shot)
不给例子,直接下命令,适合模型已经很熟悉的问题、结构清晰的任务。
🧠 概念:
Zero = 0,意思是你不给任何例子,直接告诉模型:“请你做这件事”。
🔍 示例:
请判断这段评论的情绪: “这电影好得让我差点哭了。” 请只回答:正面 / 中性 / 负面
🧾 模型输出:正面✅
② 一个样本提示(one-shot)
给一个示例当“样本”,适合任务格式比较复杂,但不需要太多指导的场景。
🧠 概念:
你先给模型一个例子,让它模仿这种结构,继续做下一个。
🔍 示例:
示例: 评论:“我喜欢这个产品,很实用。” → 正面
请判断: 评论:“太难用了,用一次就删。” → ?
🧾 模型输出:负面✅
③ 多样本提示(Few-shot)
让模型学着做,适合你要教模型遵循某种结构、风格,或者让它学某种判断规则。
🧠 概念:
Few = 少量,一般 2~5 个例子,帮模型“理解任务逻辑”。
🔍 示例:
示例1: 评论:“这电影真棒!” → 正面
示例2: 评论:“一般般,没什么特别。” → 中性
示例3: 评论:“真是浪费时间。” → 负面
请判断: 评论:“剧情拖沓,演技也一般。” → ?
🧾 模型输出:负面 ✅
📊 三种提示对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
✅ 一句话总结:
Zero / One / Few-shot 提示的核心在于:“你给模型看多少范例,它就学多少套路。”
2.设定提示
语言模型就像一个“万能演员”——你告诉它演谁、做什么、在什么场景,它就能模仿得像模像样。
所以我们要通过三种提示方式来“导演”它:
① 角色提示
✅ 概念
告诉模型“你现在是某种身份”。 它会根据这个身份自动调整说话方式、语气和知识范围。
🧠 类比
就像你对朋友说:“你扮演老师教我这个题”,对方立刻语气变认真。模型也是一样。
📝 示例
你是一个旅游导游,我在阿姆斯特丹,我想看博物馆,请推荐三个景点。
💡 变体:加入风格
你是一个幽默风趣的旅游导游……
模型可能会调皮地说:
想看博物馆?那一定不能错过梵高的“画疯子展览”!走,一起穿越艺术时空~
② 系统提示
✅ 概念
告诉模型“你该怎么做”,比如:
-
输出格式要求 -
不要废话 -
使用什么语气
🧠 类比
像你点外卖时说:“放门口就行,不用敲门”。
📝 示例
请判断下面这条电影评论的情绪,只回复 POSITIVE / NEUTRAL / NEGATIVE,不要加其他内容。 评论:”Her 这部电影让我不安,但也很深刻。”
✅ 结果
NEGATIVE(消极)
为什么加“只回复标签”很重要?
否则模型可能会说:
这是一部引发思考的电影,情绪复杂……
这就不是我们要的结果了。
③ 上下文提示
✅ 概念
告诉模型“你现在是在什么背景下工作”,让它知道更多信息。
🧠 类比
比如你说:“还记得昨天我们讲到的项目吗?” → 这就是提供上下文,别人听了就不会误会你讲的是新话题。
📝 示例
背景:你正在写一篇关于80年代街机游戏的博客。请你推荐3个可以写的文章主题,并简单介绍每个主题内容。
✅ 结果
-
街机机台设计演变史 -
从木质机箱到未来感造型,游戏不仅是内容,也是视觉享受。
-
-
像素艺术的前世今生 -
讲述早期技术限制下的艺术创意,今天反而成为复古潮流。
-
-
影响一代人的经典街机游戏 -
盘点太空侵略者、吃豆人等不朽 IP 的诞生与影响力。
-
对比:三种提示方式比较
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
✅ 使用建议(组合套路)
你可以组合这些提示来打造更强的提示句:
你是一个经验丰富的数据分析师,当前在处理客户满意度调查。 请你以专业简洁的语气,总结下列调查结果的三个关键趋势,返回 Markdown 格式的项目符号列表。
3.后退一步提问
什么是Step-back Prompting?
Step-back 的意思是“先退一步想一想,再来动手”。
这个技巧的目标是:不要直接叫模型做事,而是先让它“思考方法”,然后再解决问题。
为什么要这样做?
很多时候,大语言模型(LLM)直接答题会答错; 但如果你先引导它“怎么思考、有哪些选项”,它就会更靠谱。
🧠 类比理解
你问一个实习生:“写一份产品介绍文案。” 结果他写得四不像。
但如果你换句话问:
“你觉得一个好产品文案要包含哪些要素?列出来,再试着写一份。”
他表现是不是会好很多?模型也是一样!
📌 示例 1:写游戏剧情(对比)
❌ 直接提示:
写一个第一人称射击游戏的新关卡剧情。
🧾 模型输出:
你被敌人围困在城市里,要打出一条血路,穿过废墟,干掉敌人… (很套路)
✅ Step-back 提示
Step 1:先问“常见的好关卡设定有哪些?”
请列举5种在第一人称射击游戏中常见且具有挑战性的关卡场景设定。
🧾 模型输出:
-
废弃军事基地 -
僵尸小镇 -
外星飞船 -
网络黑客城市 -
水下研究站
Step 2:再要求写剧情
现在请以“水下研究站”为背景,写一个新关卡剧情,用一段话描述。
🧾 模型输出:
你被派往一座废弃的深海实验室,那里弥漫着诡异电波和失踪科学家的回音……
📌 示例 2:写道歉信
❌ 直接提示
写一封道歉信,给因为发货延迟而不满的客户。
🧾 模型输出:
对不起,由于不可抗力导致延迟,我们深感歉意……
✅ Step-back 提示
写好一封道歉信,最重要的三个要素是什么?
🧾 模型输出:
-
说明问题发生的原因 -
表达真诚道歉 -
提供补偿或解决方案
好的,请你基于这三点,为客户写一封道歉信,保持语气真诚、语言简洁。
🧾 模型输出:
尊敬的客户,非常抱歉您近期的订单出现了延迟。此次延误是由于仓库系统更新导致的物流排队,我们对此深感抱歉…… (内容更真诚、针对性更强)
对比:Step-back 提示 vs 直接提示
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
如何写一个 Step-back 提示?
你可以按照以下结构来写:
任务目标:你想让模型完成的事
Step 1:请你列出 [完成这类任务的关键要素/常见思路/适用结构]
Step 2:根据上述内容,请你完成这个任务。
🧪 示例模板
任务目标:写出一个AI产品的宣传句子
Step 1:请列出一个优秀AI产品文案应包含的3个特点
Step 2:结合这些特点,为产品“小云雀AI剪辑工具”写一句宣传文案
🧾 模型可能输出:
“小云雀AI,一句话生成爆款视频,创作像呼吸一样简单!”
✅ 总结一句话
Step-back Prompting = 先思考,再执行
让模型先当“策划”,再当“工人”,结果往往更靠谱。
4.逐步思考提示
什么是 Chain of Thought(CoT)?
Chain of Thought(简称 CoT)是一种提示技巧, 通过引导模型“一步一步地思考”,来提高逻辑推理和复杂问题的回答质量。
为什么要用 CoT?
大模型(LLM)在遇到逻辑问题、数学题、多步骤任务时,如果直接回答,很容易出错。 而如果你提示它“请一步一步来”,它就像学生解题一样,会先思考过程,再得出答案,正确率明显提升。
📖 类比理解
就像你做数学题,不是直接跳出答案, 而是写草稿:
-
第一步:已知…… -
第二步:我们可以推导出…… -
最后得出答案是……
模型也可以用这个方式“想事情”。
📌 示例 1:不用 CoT,模型答错了
问:我3岁时,我的伴侣是我年龄的3倍。现在我20岁。我的伴侣多大了?
🧾 模型直接输出:63岁
❌ 明显错了。
📌 示例 2:加入 CoT,模型答对了!
问:我3岁时,我的伴侣是我年龄的3倍。现在我20岁。我的伴侣多大了? 请一步一步思考(Let’s think step by step)。
🧾 模型输出:
第一步:我3岁时,我的伴侣是 3 × 3 = 9 岁
第二步:现在我 20 岁,说明我比小时候大了 17 岁
第三步:我的伴侣也增加了 17 岁 → 9 + 17 = 26 岁
答案是:26 岁 ✅
📌 示例 3: One-shot CoT 提供范例
Q: 当我哥哥 2 岁时,我是他年龄的两倍。现在我 40 岁,我哥哥几岁?
A: 我哥哥 2 岁时,我是 4 岁。年龄差是 2 岁。我比他大。 现在我 40 岁,所以他是 38 岁。答案是 38。
Q: 我 3 岁时,我的伴侣是我年龄的3倍。现在我20岁,我的伴侣几岁? 请一步步思考。
🧾 模型输出:
我3岁时,伴侣是 3 × 3 = 9 岁
年龄差是 6 岁 → 我比他小6岁
现在我 20 岁 → 伴侣是 20 + 6 = 26 岁
📌 示例 4:用于生成代码逻辑
产品名字是“小云雀AI”,请写一段产品介绍文案。 但请你先一步一步说明:一个成功的AI产品介绍需要包含哪些要素?
🧾 模型输出:
-
强调核心功能 -
用简单语言传达价值 -
有场景感或使用画面
基于以上: “小云雀AI,自动生成爆款短视频,一句话创作,灵感不再等待。”
对比: CoT vs 普通提示
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
CoT 提示模板(推荐结构)
任务描述(如:请解决以下逻辑问题)
请一步一步思考,写出你的推理过程,然后再给出最终答案。
【问题内容】
🧪 示例模板应用
问题:一辆火车上午9点出发,以每小时60公里的速度行驶。它要到达240公里外的城市。 它几点到达?请一步一步思考。
🧾 模型输出:
-
距离是240公里 -
速度是60公里/小时 -
时间 = 距离 ÷ 速度 = 240 ÷ 60 = 4小时 -
出发时间是9点 → 到达时间是13点(下午1点)
✅ 一句话总结
CoT 提示 = “模型,请像人一样想事情”, 把思考过程写出来,最后再给答案,更靠谱。
5.自一致性提示
什么是 Self-Consistency?
Self-Consistency 是在 Chain of Thought(CoT)的基础上, 让模型用不同方式“多次思考”,然后从这些回答中选出最一致的那个作为最终答案。
为什么需要它?
即使使用 CoT,模型的回答也可能受温度参数等影响, 导致它每次“思考路径”不同,答案也不一样。
但如果你:
-
多问几次 -
对每次推理结果做统计 -
选择最常出现的答案
就能得到一个更可靠的结果。
📖 类比解释
你问一个问题,10个人各写一遍推理过程,如果有 7 个人都得出“答案是B”,那B很可能是对的。
模型也是一样,它就是你团队里的 10 个“脑子”。
🧪 应用流程
-
同一个问题,提示模型用 CoT 思考 -
用较高温度(如 0.8)采样 多次回答(例如 10 次) -
比较每个回答的最终结果 -
选出出现频率最高的那个答案作为最终输出
📌 示例:邮件是否重要?
EMAIL 内容:
Hi, 我注意到你的网站用了 WordPress,一个非常棒的开源系统。 不过你联系表单有个小 bug,我加了截图,在输入名字时会弹出 JavaScript。 你也可以不修,挺有意思的。
Cheers, Harry the Hacker
请判断这封邮件是否属于“IMPORTANT” 或 “NOT IMPORTANT”, 请一步一步思考并解释为什么。
🧾 模型回答尝试(1)
-
邮件提到了网站存在 XSS 漏洞 -
存在安全隐患 -
尽管语气轻松,但内容严重
结论:IMPORTANT(重要)
🧾 模型回答尝试(2)
-
邮件语气幽默 -
没有明确要求修复 -
没有显著紧急性
结论:NOT IMPORTANT(不重要)
🧾 模型回答尝试(3)
-
提到一个真实漏洞 -
虽然不是正式报告,但影响不小 -
建议尽快检查网站
结论:IMPORTANT(重要)
📊 分析结果
|
|
|
|---|---|
|
|
|
✅ 最终结果:选择“IMPORTANT”作为更可信答案
⚙️ 技术设置建议
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
🛠 提示模板推荐
请对下面的问题进行一步一步的逻辑分析,并给出最终结论。
问题:XXX
请重复此过程多次,并记录最终结论。选出最常见的那个作为最终答案。
✅ 一句话总结
Self-Consistency 就是:多次推理 + 多人投票 + 选最稳的那个答案
特别适合:
-
安全、法律、财务类任务 -
需要准确分类的业务系统 -
对错误容忍度低的AI场景
6.思维树提示
什么是 Tree of Thoughts(ToT)?
Tree of Thoughts(简称 ToT)是一种比 Chain of Thought 更强的推理方法。
它不只沿着一条线思考,而是像树枝一样,探索多条推理路径,然后比较、筛选最优结果。
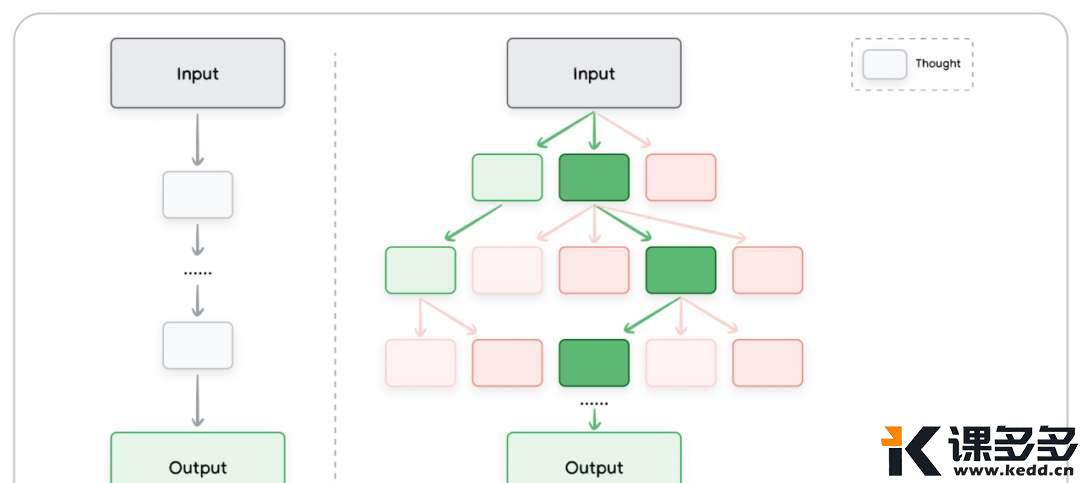
ToT 和 CoT 的区别是什么?
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
A2 → B2 → 答案2
A3 → B3 → 答案3
ToT 就像走迷宫时,不只走一条路,而是尝试多条路,然后选最短那条。
📖 类比说明
-
CoT 就像你自己在纸上一步一步写推理 -
ToT 就像你组了三支小队,分别从不同方向出发,最后比谁找到的答案最好
📌 示例:创作解谜游戏关卡
请设计一个解谜游戏的新关卡。 要求:玩家进入一个神秘场所,依靠线索一步步解开谜题。 输出方式:请列出多个构思方向,每个方向都有一个简单情节描述。
🧾 模型 ToT 输出(构建三个“树枝”):
方向一:废弃图书馆
-
玩家进入荒废图书馆 -
必须解读书籍顺序和藏在书页中的符号 -
解开密码门,进入下一层
方向二:沉船遗迹
-
玩家在水下探险 -
收集海洋生物骨骼组成“星座图” -
解锁隐藏舱室的古代信息
方向三:梦境空间
-
玩家在梦中穿梭场景 -
每个梦都有碎片式信息 -
最终拼成一段过去的真相
✅ 分析与选择
可以从多个维度来选出最优答案:
-
哪个最有创意? -
哪个更容易实现? -
哪个最适合游戏故事线?
例如:选择“废弃图书馆”作为主线,其他两个作为备选。
🧪 更进一步的 ToT 实践流程:
-
提出任务或问题 -
生成多个不同思路(分支) -
每条思路展开若干推理步骤 -
比较所有路径得出的答案 -
选择一个最佳输出结果
🛠 提示模板推荐
请为以下问题/任务设计多个解法思路,每个思路请详细展开1~2步的推理,并给出最终答案或建议。
问题:[在这里写任务内容]
🧾 示例应用:AI写广告脚本
问题:写一段30秒广告脚本,推广“智能健身镜”。
🧾 模型输出:
思路一:日常生活转变型
-
开头:加班后的疲惫 -
镜头切换:AI健身镜指导短时高效训练 -
结尾口号:你不再需要健身房,镜子就是教练
思路二:科技未来型
-
开头:科技冷色调未来城市 -
镜头:镜子自动识别体型、推荐训练方案 -
结尾:改变未来,从这面镜子开始
思路三:情感共鸣型
-
开头:父亲陪孩子练体能 -
镜头:健身镜记录进步,生成成长影集 -
结尾口号:AI见证你们一起变强
ToT 的优劣分析
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
✅ 一句话总结
Tree of Thoughts = 让模型同时尝试多个想法,然后挑最好的一个!
是多路径探索、多版本思考的进阶版提示技巧,适合复杂决策或创意任务。
7.先思考再行动提示
🧠 什么是 ReAct 提示技巧?
ReAct = Reason + Act
意思是:模型先“思考”,然后“采取行动”,再根据行动结果继续思考,形成一个思考-行动-观察-再思考的循环。
这是提示工程中迈向“智能代理”模型的关键技术之一。
🧭 它有什么用?
ReAct 特别适合:
-
需要调用工具或外部信息的任务(如搜索、数据库查询、API 调用) -
多步、互动性强的问题解决过程 -
具备一定“探索”需求的复杂任务
🧠 类比理解
ReAct 就像你派一个 AI 助理去查资料。它会这样做:
-
先思考:“我需要什么信息?” -
去 Google 搜索 -
看看搜索结果 -
再思考:“这些够不够?还要查什么?” -
重复这个过程,直到得出答案
🔁 典型 ReAct 流程结构
Thought → Action → Observation → Thought → Action → … → Final Answer
📌 示例任务:M乐队成员有几个孩子?
目标:让 AI 通过搜索工具找出答案,而不是自己“猜”。
🧾 提示输入(使用 LangChain 框架):
任务:请告诉我 Metallica 乐队成员一共有多少个孩子。 你可以用搜索工具查询每个成员的情况。请一步步思考并逐步获取信息。
📟 ReAct 实际运行日志:
Thought: Metallica 有 4 个成员。
Action: 搜索 James Hetfield 有几个孩子
Observation: 3 个
Thought: James 有 3 个孩子,目前统计 3
Action: 搜索 Lars Ulrich 有几个孩子
Observation: 3 个
Thought: 现在总数是 6
Action: 搜索 Kirk Hammett 有几个孩子
Observation: 有两个儿子
Thought: 现在总数是 8
Action: 搜索 Robert Trujillo 有几个孩子
Observation: 2 个
Final Answer: 10 个孩子 ✅
⚙️ 技术实现建议
使用工具(以 Python + LangChain 为例):
-
LangChain 框架(处理 ReAct 循环) -
Google Search API(例如 serpapi) -
模型:VertexAI、GPT、Claude 等均可接入
🧾 示例代码片段(以 VertexAI + serpapi):
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain.llms import VertexAI
llm = VertexAI(temperature=0.1)
tools = load_tools(["serpapi"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("How many kids do the band members of Metallica have?")
🛠 提示设计模板
你是一个能主动执行任务的智能助理。
你可以通过 [搜索/API/计算工具] 获取外部信息。
请遵循: Thought → Action → Observation → Thought … 直到得出答案。
问题:______
🔎 ReAct 的常见动作类型
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
📊 ReAct 优劣势分析
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
✅ 一句话总结
ReAct 提示是 LLM 通往“智能代理”的起点, 它让模型不只是回答,而是思考后采取行动,并根据结果再调整行为。
写在最后
提示词工程听起来高大上,但核心就是清晰地与AI沟通。
最重要的秘诀就是实践,多尝试、多修改,看不同的提示词会带来什么样的结果。
想用好 AI 还是尽快学英文吧。
我最近也准备用 AI 给自己安排学习计划了,如果学了之后有明显的提升,也会来分享方法的。
这次努力把英文都翻译成中文,但是有时候不用英文真的很奇怪,感觉很难解释到位。
而且英语才是 AI 的母语,有些词还是用英语写更贴切,而且识别准确度也更高,相信你要是平时没少看我的文章,应该也能发现这点。
本文主要是给初学者打基础用的,地基不牢,再往上搭什么都很容易倒,只是知其然,不知其所以然。
再往后基本就要学代码了,如果想要这个白皮书的英文原版,可以找我领。
今天就酱八,明天继续聊AI。




暂无评论内容