
就在刚刚 ,DeepSeek 线上模型版本已升级至 V3.1!
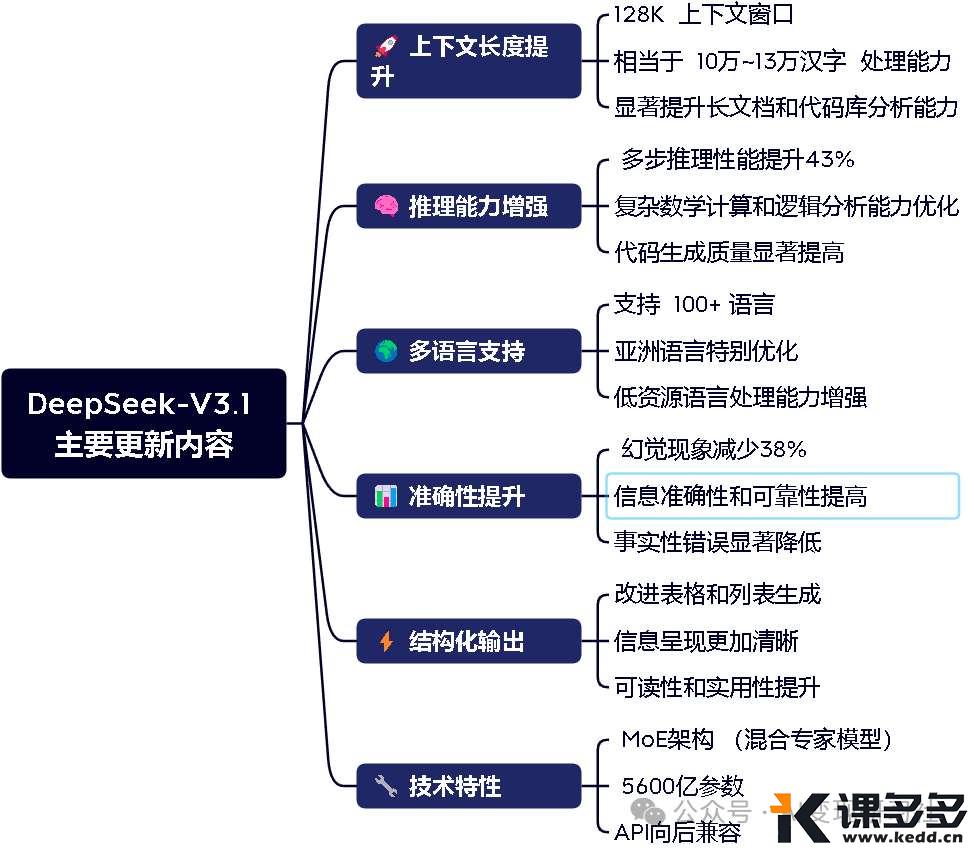
8 月 19 日,DeepSeek 小助手在官方群发布信息称,DeepSeek 线上模型版本已升级至 V3.1,上下文长度拓展至 128k,欢迎前往官方网页、APP、小程序测试,API 接口调用方式保持不变

官方称:本次升级后:适合长文档分析、推荐用于复杂推理任务、多语言场景表现优异
DeepSeek 的不足
实测,前端代码等优点不提,升级后 DeepSeek V3.1 仍有不足
1、R2 迟迟未发布
DeepSeek 有两个版本,一个思考版R系列,一个日常对话版V系列
今年春节让DeepSeek在全球名声大造的是R1
DeepSeek R1 模型已完成小版本升级,当前版本为 DeepSeek-R1-0528。此前所传 8 月份 R2 发布小时官方否认。
DeepSeek 初期表现出色,曾经一度冲上全球 AI 排行榜 5 名 左右
但随着 Kimi K2, Qwen3、GPT5 发布,DeepSeek 已经跌出前十,落后于同为开源+国产的 Kimi K2, Qwen3
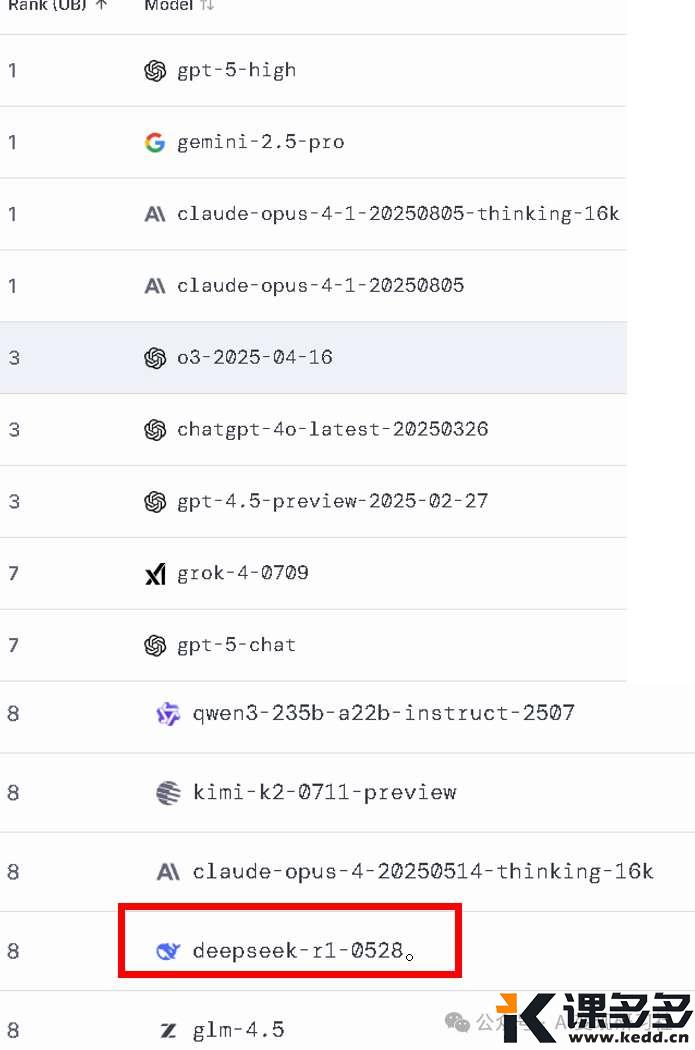 图源:https://lmarena.ai/leaderboard ,20250819
图源:https://lmarena.ai/leaderboard ,20250819
2、幻想率依然偏高
生成式 AI 的通病。不过 DeepSeek 出奇的高。R1
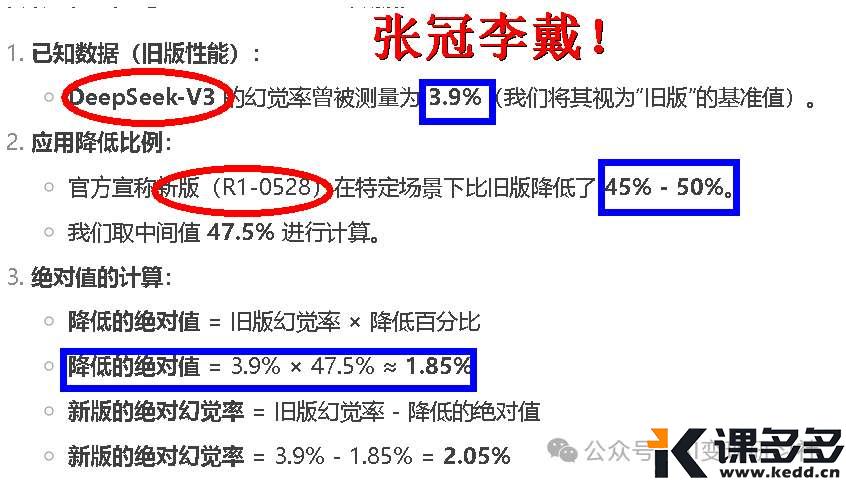
此前,R1 幻觉率为 14.3%,V3 为 3.7%.
本次减少 38%,就是说 V3 幻想率现在是 2.5%
只能说亡羊补牢,让笔者受不了的是网上已经充斥着大量用 DeepSeek 胡编乱造的信息,简中圈已经被污染
3、逻辑依然混乱
新版 V3.1 连 V3 和 R1 的区别都搞不清楚
4、不支持多模
仅支持文字,就是单模
支持读图,读视频,就是多模
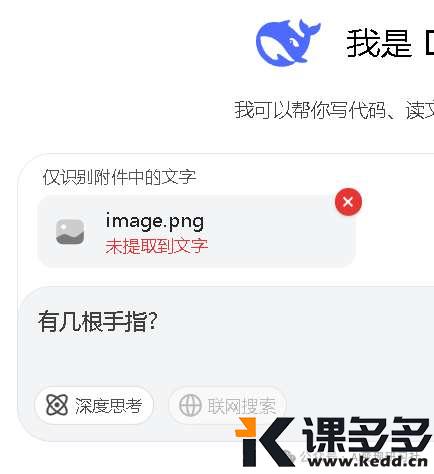
如果给 DeepSeek 一张六指琴魔的图片
好消息是 DeepSeek 不会把六根手指看做 5 根手指
坏消息是 DeepSeek 根本不能读图
5、上下文 128K 长度还是太小
V3 的定位不是复杂思考,而是文本分析,128K 还是太小了
百度、Kimi,GPT,都超过 256K,更不要说 Gemini 惊人的 1M 上下文,128K 还是太小了
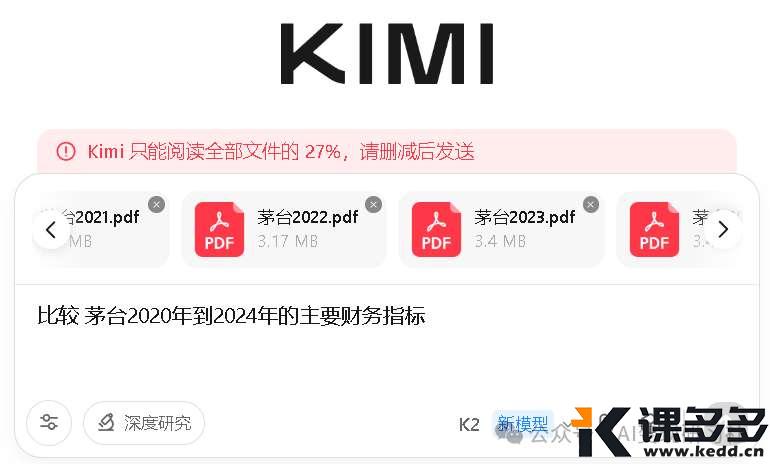
上传 5 部茅台年报,每部15-18万字,DeepSeek 说它只能读 12%
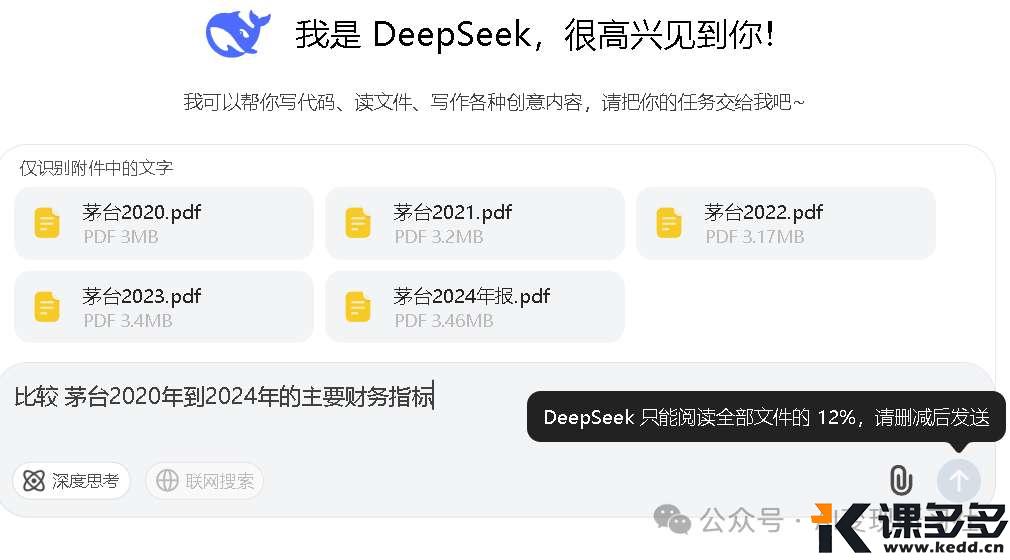
而 Kimi K2 能读 25%
6、基础功能缺失
除了 AI 能力外,基础功能也缺失,比如
-
无法搜索历史消息 -
不支持文档置顶 -
不支持隐私对话 -
不支持“用户数据投喂大模型”关闭按钮
一句话,DeepSeek 作为大红大紫的国民级 AI,它的出现,让中国 AI 和开源 AI 百花齐放
但小时了了大未必佳?后继版本开发进度不尽如人意
要挽回颓势,还是要等 R2 发布,但时至今日,备受期待的 DeepSeek R2 版本尚未公布具体发布时间。同时外媒报道 DeepSeek R2 在训练时由于芯片的问题导致发生严重错误,因此可能其发布还会再晚一些。
希望尽快看到 DeepSeek AI 模型能力和工程能力的双双提升!





暂无评论内容