
相信大家都已经习惯让 AI 去分析图片了,无论是提取图片中的文字,还是识别图片包含的内容,都是非常大的助力。
但是,能直接识别视频的 AI 你用过吗?
今天介绍的这款就能够识别视频,不仅是里面包含的文字,就连视频里面的画面内容都能识别,不得不说,十分强大。
它就是文心一言,官网在这:https://yiyan.baidu.com/chat
打开后是长下图这样的,我们可以直接点击视频按钮上传视频:
我先拿这个试试:
我先让它识别下视频里的内容,提示词:
帮我识别下这个视频里的内容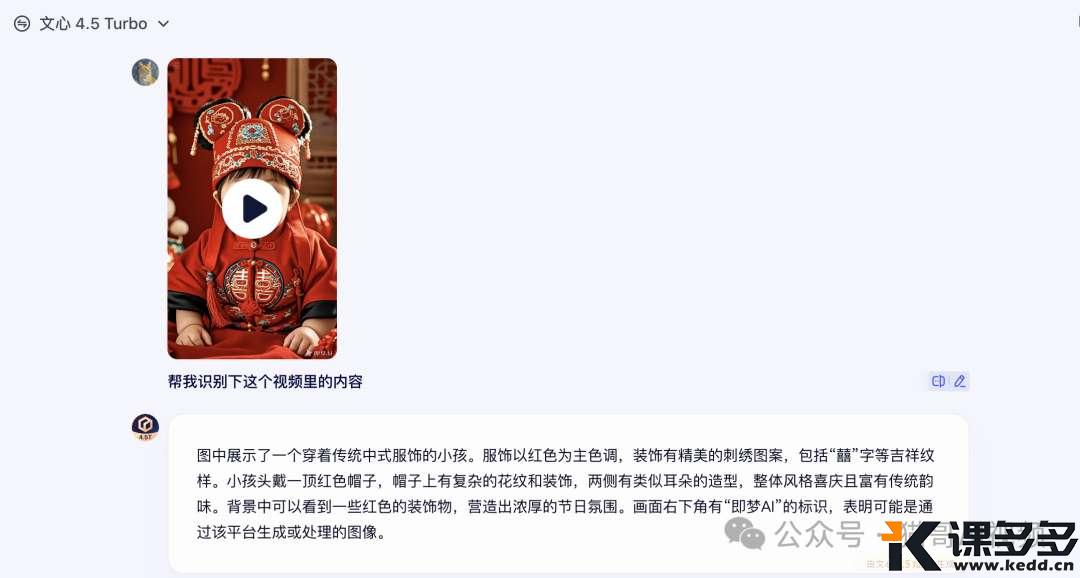
看得出来,识别得还是挺仔细的。
下面我们让它识别下视频里面说的话,提示词:
这个视频里面的人物说了什么话
因为我没有添加字幕,所以它是直接识别音频的,目前识别得完全没有问题!
我们加下难度,让它输出某个时间点的话语,提示词:
在第三秒的时候,该背景音说的是什么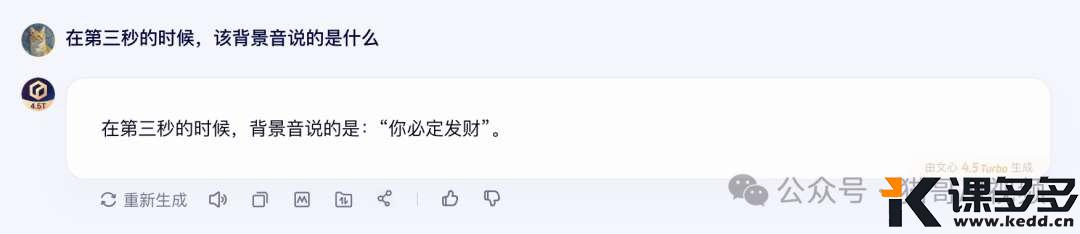
这个也识别对了!
突然想到一个问题,就是我们之前去拉片的时候,不是得在剪映中一帧帧拖动去看每个画面的内容吗?
要不,我干脆让 AI 帮我们识别出每一个分镜,那岂不是我都不需要去拉片了,就能直接知道每个分镜的内容,直接拿这些画面直接去生成画面即可。
我们拿这个视频试试:
提示词:
帮我对该视频进行拆解成几个分镜,并且提供这些分镜的画面内容给我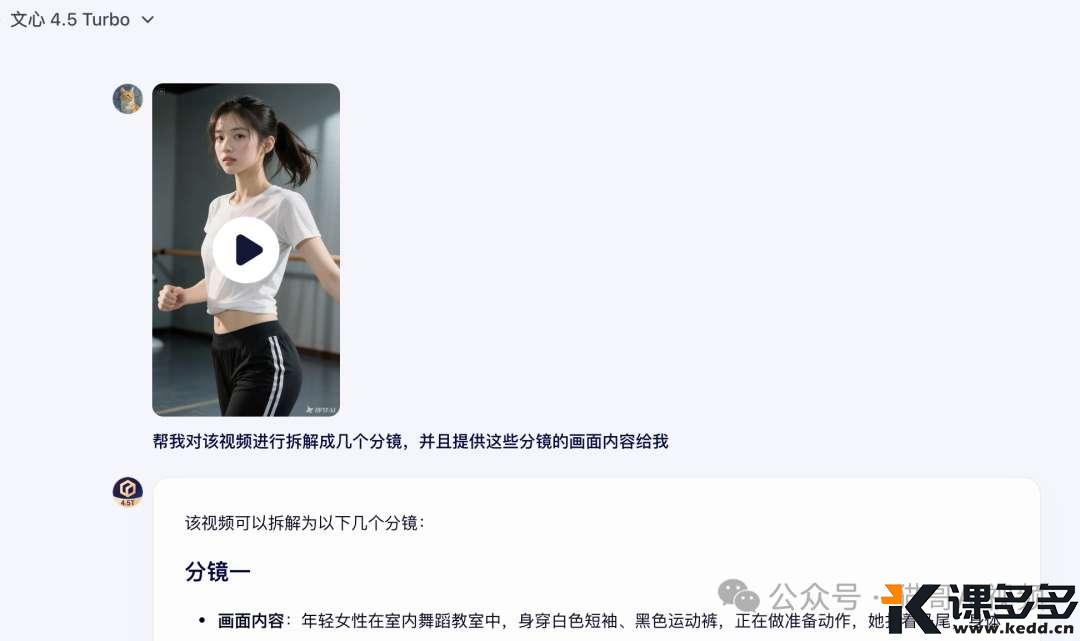
该视频可以拆解为以下几个分镜:分镜一画面内容:年轻女性在室内舞蹈教室中,身穿白色短袖、黑色运动裤,正在做准备动作,她扎着马尾,身体微微前倾,双臂自然摆动,似乎在调整呼吸和节奏,背景是灰色的墙壁和木质地板,墙边有把杆,地面有胶带标记。分镜二画面内容:年轻女性开始在舞蹈教室中跑步,她步伐轻盈,双臂有节奏地摆动,马尾随着跑动而晃动,展现出活力与动感,背景依旧是舞蹈教室的内部设施。分镜三画面内容:年轻女性跑到舞蹈教室门口,继续向室外跑去,画面捕捉到她跑动的背影,她逐渐远离镜头,向着一个有更多建筑和开阔空间的地方跑去。分镜四画面内容:镜头切换到俯视角度,展示年轻女性在一条城市街道上跑步。街道两旁是多层建筑,路面干净整洁,有车辆停放和行驶,女性在道路中间奔跑,身影逐渐变小,背景中的建筑和街道设施清晰可见,展现出一种自由和坚持的氛围。拆解得确实不错,确实是四个分镜,并且画面内容都对得上。
更多使用方式等待大家去探索,快去试试吧!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END





暂无评论内容