


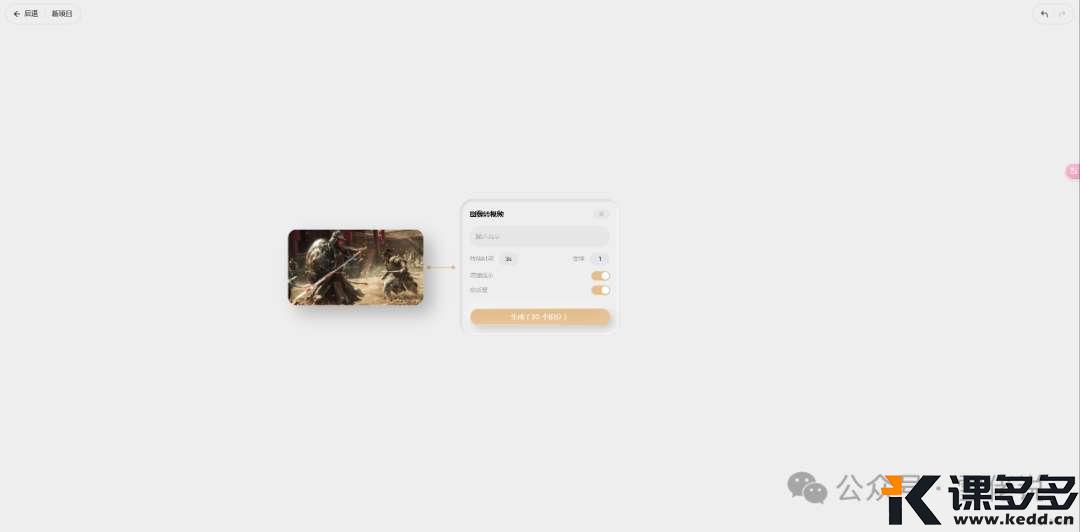
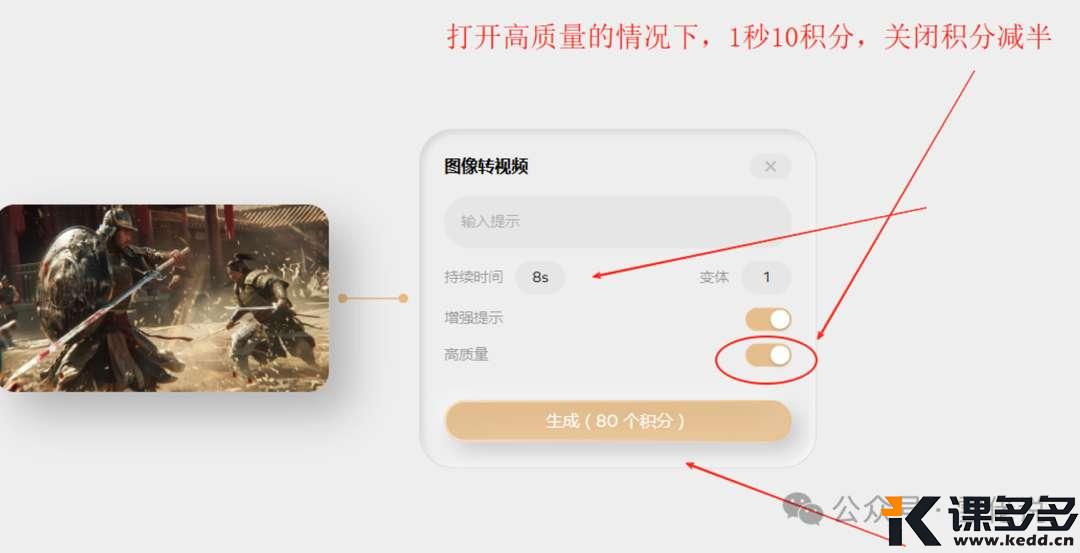
通过上图,大家可以看到,
持续时间,就是视频生成的时间长度,
最短可以选择1秒,最长10秒,
1秒钟是10积分,你可以1S-10S任意输入,
这个是高质量开启的情况下所花费的积分,
如果关掉高质量,积分减半。
为了看下生成质量,我的高质量是开启的。
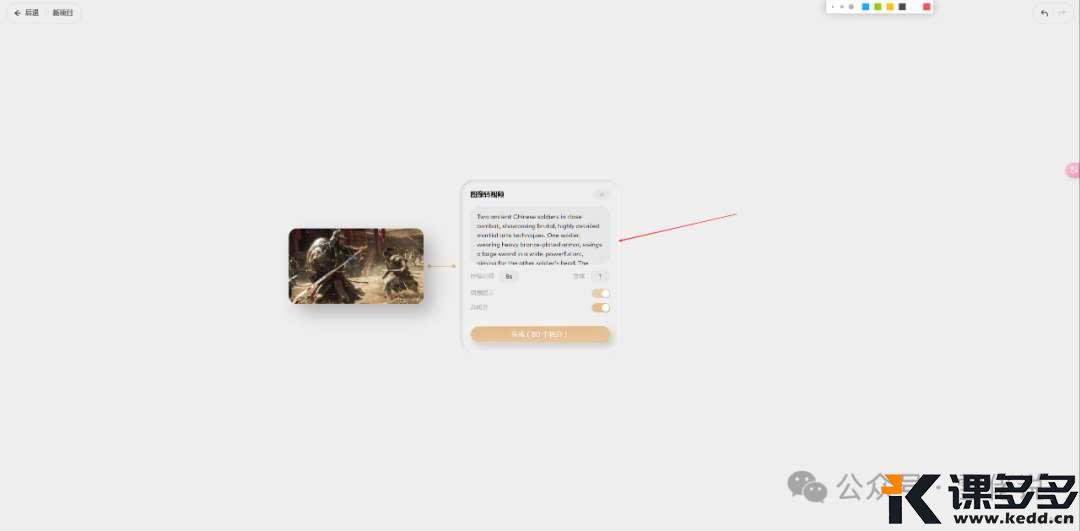
输入过提示词之后,直接点击生成,
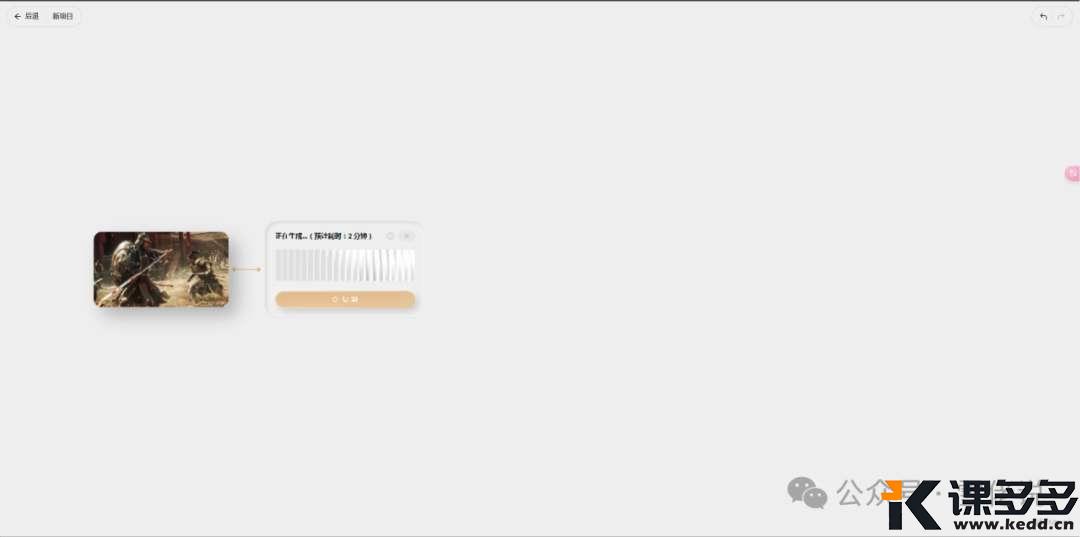
上面写的是2分钟,
其实测试下来,
实际生成一个视频的时间是5分钟。

第一个视频生成之后,如果满意的话,
你还可以继续点视频卡片右边那个黄色+号,
继续延长视频,
因为免费积分不多,
雪佬只延长了一次,
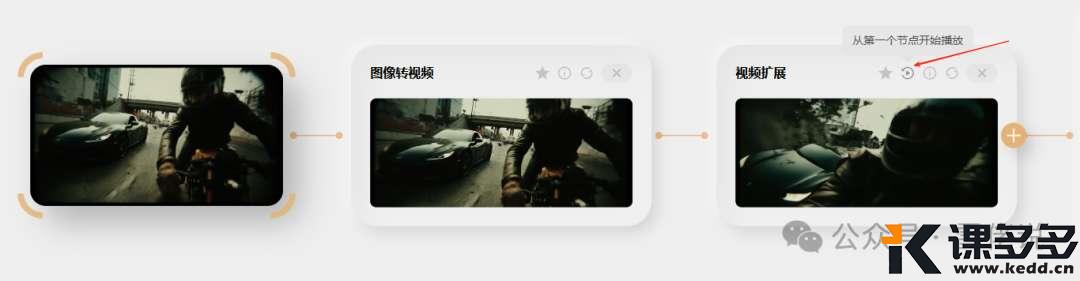
这里值得一说的是这个播放按钮,
当你第二个视频生成之后,
你点击这个播放按钮,
它就会第一个视频和第二个视频连续播放,
这个功能就非常的方便,
你可以直观的在网页端就能看到连续的镜头,
故事的连续性很直观的就能看到了,
不需要把视频导入到视频剪辑软件里了。
好了,以上就是整个视频生成的操作步骤,
看到这里,
各位观众老爷一定很想看看生成结果如何,
我知道你很急,
我这就发出来。

各位观众老爷可以看看这个视频怎么样,
前8秒是第一个镜头,
后2秒是延长的镜头,
延续的这个2秒镜头还是不错的,
丝滑,
至于这个视频的生成效果,
雪佬觉得,中规中矩吧,
下面这个古代士兵战斗的镜头,
就体现出很差了,
请看VCR,
看过上面视频的观众老爷,
一定会,惊呼,
什么鬼?
人物身上像是有1万只蜜蜂在飞,
看来上点强度(指武打动作)的镜头,
MAGI-1还是不行的,
当然,这个我只是在网页端测试,
免费积分也比较少,
不能抽卡多生几次,
样本有点少,
另外雪佬的电脑也比较垃圾,
不能在本地跑,
所以,各位观众老爷也可以去官网试一试,
或者能在本地跑的朋友,
跑出来的视频,
欢迎在评论区交流经验。
那么有的观众老爷至今肯定还有个疑问,
到底什么是自回归模型,
那么,官方的说明是这个
我们提出了 MAGI-1,这是一个世界模型,它通过自回归预测一系列视频块(定义为固定长度的连续帧片段)来生成视频。MAGI-1 经过训练,可以去除随时间单调递增的单块噪声,从而实现因果时间建模,并自然支持流式生成。它在以文本指令为条件的图像到视频 (I2V) 任务中表现出色,提供了高度的时间一致性和可扩展性,这得益于多项算法创新和专用的基础架构堆栈。MAGI-1 还通过逐块提示支持可控生成,从而实现流畅的场景过渡、长时域合成和细粒度的文本驱动控制。我们相信,MAGI-1 为统一高保真视频生成、灵活的指令控制和实时部署提供了一个充满希望的方向。
另外,我也去问了GPT,
它给出的答案是这个,
自回归模型(Autoregressive Model)是一种常见的统计模型,它在生成数据时依赖于先前的生成结果。在生成式AI中,尤其是在文本生成和视频生成领域,自回归模型可以根据先前的输入或部分输出,逐步预测并生成后续的内容。
自回归模型的工作原理:
-
逐步生成:模型通过已经生成的部分数据来预测下一个数据点。例如,在文本生成中,模型会根据已经生成的单词或句子,预测下一个单词的出现概率。视频生成中,也是根据生成的帧或画面,预测下一帧的内容。
-
阶梯依赖:生成的每一部分都依赖于前面生成的部分。模型每一步的输出都会影响接下来的输出。
-
训练方式:在训练时,自回归模型通常通过已知的输入来学习如何生成新的内容。例如,给定一个图像,模型可以对学会渐进生成每个像素点,或者给定一段视频,它可以学习如何根据前一帧的内容生成下一个帧。
自回归模型在AI视频生成中的应用:
在AI视频生成中,自回归模型的核心思路是通过前面的帧信息来生成后续的帧,从而创建连贯且自然的动态画面。例如:
-
逐帧生成:自回归模型可以通过生成第一帧视频后,依赖于该帧的信息生成第二帧,接着是第三帧,直到整个视频生成完成。
-
连续性和一致性:为了保证生成的每一帧都符合逻辑且与前面的帧保持一致,模型需要通过自回归的方式捕捉视频中的时间依赖关系。
这种方法通常用于需要高质量连续性的视频生成,例如:动作捕捉、人物动态、场景转换等,它可以帮助AI生成更加平滑和一致的视频内容。
优点:
-
连贯性:由于每一帧或每个部分都依赖于前面的内容,生成的视频或文本可以保持连贯性和一致性。
-
细节控制:在生成过程中,模型能够捕捉到短暂的动态变化。
缺点:
-
计算复杂度高:由于每一帧都依赖于前面的内容,生成过程往往比较慢,需要前面的计算资源。
-
长序列生成难度大:生成非常长的视频序列时,前面的错误可能会影响后续的生成质量。
总体而言,自回归模型在AI视频生成中提供了一种自然且有效的方式来创建动态且一致的内容,广泛评估生成式模型中,如生成视频、文本、音频等。
那么雪佬仍然看得云里雾里,
所以,雪佬对GPT说:
我是小学生,请用我懂的语言概括下,
自回归模型就像是你画画的时候,记号记画下去。它会看你已经画的部分,然后根据这些部分来决定接下来的画怎么画。在做AI视频的时候,就像是一个机器人看着已经完成的画面(比如前面的一个视频帧),然后决定怎么画下一帧。
所以,AI视频生成的时候,每一帧画面都是基于前面的画面静止的,这样视频就会连贯、不突兀。不过它也有一点麻烦,因为机器人要不断根据前面的内容决定就好,有时候会花比较多时间去完成。






暂无评论内容